


MapReduce数据分析

MapReduce,作为一种革命性的分布式计算框架,已成为处理大规模数据集的核心技术,该框架最初由Google提出,并迅速被Apache Hadoop项目采用和普及,MapReduce的核心优势在于其能够将复杂的数据处理任务分发到多个计算节点上进行并行处理,从而显著提高数据处理效率。
MapReduce基础理论
MapReduce模型将数据处理过程分为两个基本阶段:Map阶段和Reduce阶段,在Map阶段,系统将输入数据拆分成多个独立的数据块,每个数据块由一个Map任务处理,Map任务读取输入数据,解析成键值对,然后根据用户定义的Map函数处理这些键值对,生成一组中间键值对,这些中间结果会被系统按照键值排序和分组。
在Reduce阶段,每个Reduce任务负责处理一个或多个特定的键和其对应的值列表,Reduce函数根据用户定义的逻辑处理这些数据,最终输出结果,这种模型通过简化数据操作和隐藏底层的并行处理细节,使开发者能够专注于数据的业务逻辑处理。
MapReduce作业执行流程
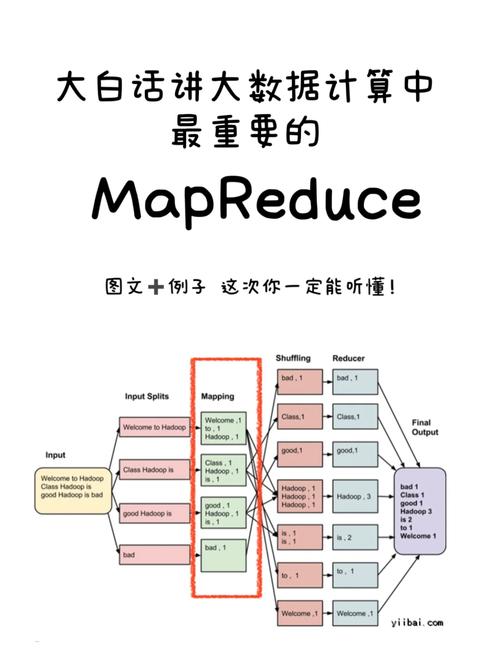
1、输入分片:输入文件被分成若干个数据块,每个数据块由一个Map任务处理。
2、Map阶段:每个Map任务读取对应的数据块,生成键值对,然后根据Map函数进行处理,生成中间键值对。
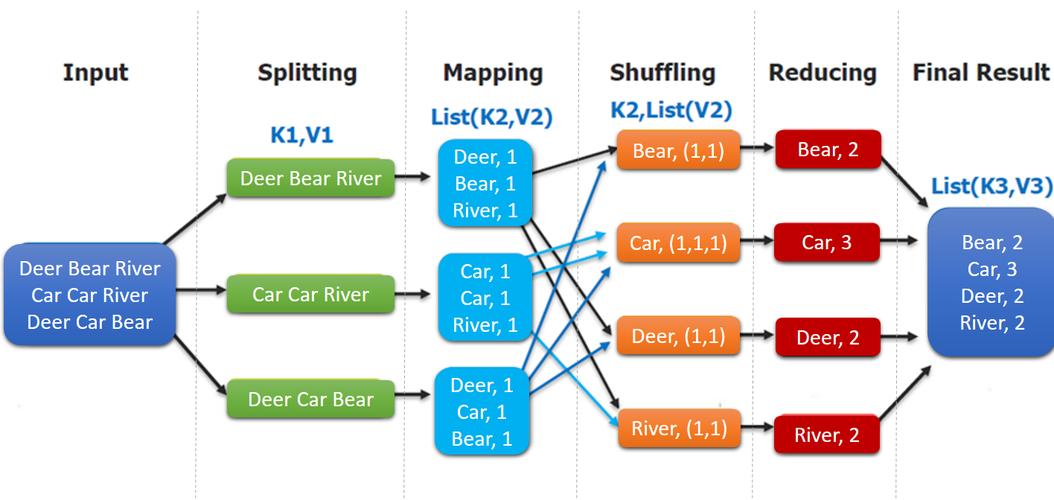
3、Shuffle和Sort:系统将Map阶段的输出按键进行排序,并将相同键的值传输给对应的Reduce任务。
4、Reduce阶段:每个Reduce任务获取到一组特定键的值列表,通过Reduce函数处理这些数据,并生成最终的输出结果。
5、输出:结果被写回到文件系统中,可以是HDFS或其他存储系统。
MapReduce在数据分析中的应用
MapReduce广泛应用于数据分析领域,尤其在处理大数据场景下表现出色,在日志分析中,MapReduce可以用来统计访问量、错误率等信息;在文本分析中,可以用来进行词频统计、倒排索引构建等任务;在科学研究中,如基因组学数据分析,MapReduce能够帮助科学家快速处理和分析大量的基因序列数据。
日志分析:处理服务器产生的大量日志文件,分析请求的成功率、错误类型等关键信息。
文本分析:对大规模文本数据进行词频统计、情感分析或建立全文搜索引擎的倒排索引。

商业智能:分析销售数据、顾客行为,为决策提供支持。
优化MapReduce作业
优化MapReduce作业是提高数据处理效率的关键步骤,一些常见的优化策略包括合理设置Map和Reduce任务的数量,压缩中间数据以减少网络传输的负载,以及选择合适的数据格式和存储方式来加快数据的读写速度,代码层面的优化,如避免不必要的数据转换和拷贝,也非常重要。
相关FAQs
什么是MapReduce最适合处理的数据类型?
MapReduce非常适合处理大规模非结构化和半结构化数据,如文本文件、日志文件和JSON文件,这是因为MapReduce能够高效地将这些数据分解成小的任务单元并行处理。
如何确定MapReduce作业中的Map和Reduce任务数量?
理想的任务数量取决于多个因素,包括输入数据的大小、集群的处理能力和并发网络带宽,增加任务数量可以提高并行度,但过多的任务可能会导致管理开销增大,反而降低效率,实践中常通过性能测试来找到最优的任务配置。
MapReduce作为一种强大的分布式计算框架,极大地简化了大规模数据处理的复杂性,通过理解其核心原理和合理应用,可以有效地解决各种数据分析问题,适当的优化措施也是确保数据处理效率和效果的关键,随着技术的不断进步,未来MapReduce将继续在数据分析领域扮演重要角色。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/995344.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复