


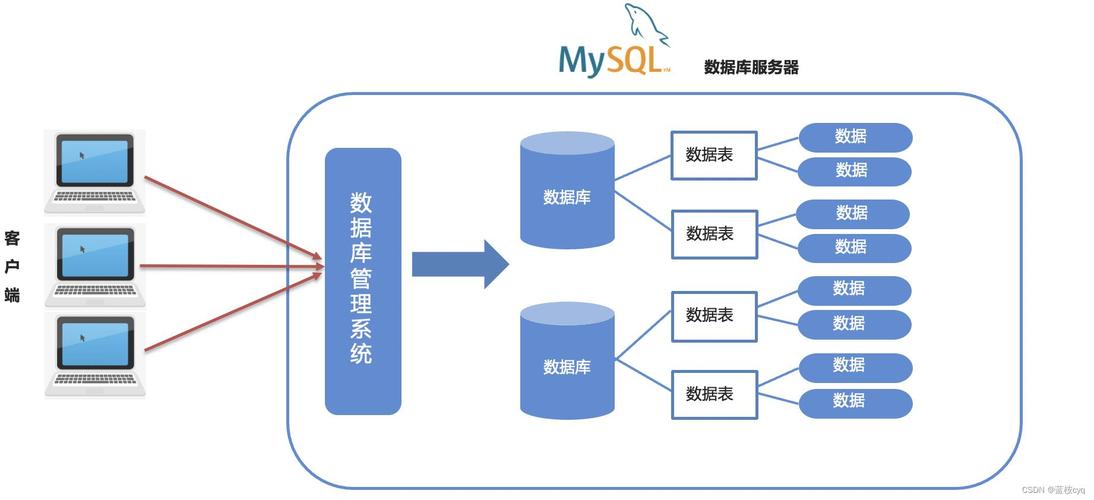
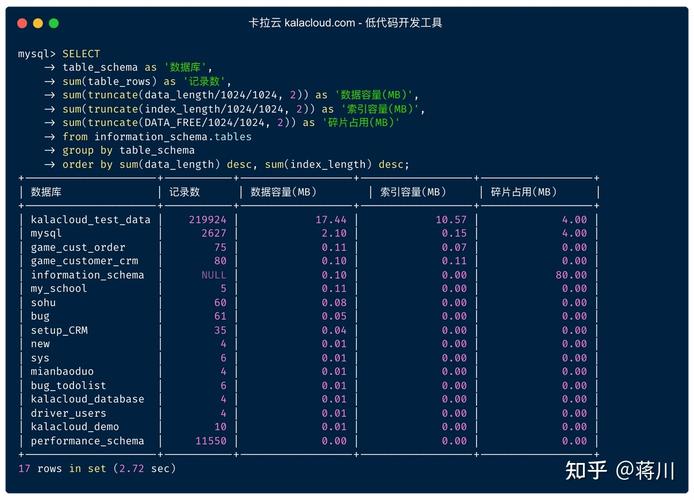
SELECT语句结合COUNT(*)函数来计算表中的记录数,而使用SHOW TABLE STATUS或第三方工具可获取表的存储大小。在数字化时代,数据已成为企业决策和运营的核心,随着业务不断扩展,数据库中的数据量急剧增加,对数据库的性能和管理提出了更高的要求,MySQL作为一个广泛应用在全球的开源关系型数据库管理系统,在处理大量数据时的表现及其优化方案尤为受到关注,理解MySQL的数据量化不仅有助于提高数据库性能,还可以帮助企业更好地规划数据存储结构,优化资源配置,本文将深入探讨MySQL数据量的内容数据量化问题,包括数据类型选择、表分区方法以及当数据量超过一定规模时的应对策略。

MySQL中的数据类型选择对数据量化管理至关重要,数据类型不仅影响数据的存储空间,还直接影响数据库的性能和扩展性,选择合适的数据类型可以减少存储空间的浪费,提高查询效率,对于数值类型,选择适当的整数类型(如TINYINT、INT、BIGINT)或实数类型(如FLOAT、DOUBLE)根据存储需求可有效减少存储空间,并提升计算速度,字符串类型(如VARCHAR、TEXT)的选择也应根据实际存储需求来决定,避免无谓的空间浪费。
表分区是处理大数据量时的一个高效手段,通过将表分成较小的部分,可以提升查询效率,简化数据管理,水平分区和哈希分区是两种常见的分区方法,水平分区按照行进行分区,适合数据可以明显分为不同逻辑块的情况;而哈希分区则通过特定的哈希算法将数据均匀分布到不同的分区,适合于数据分布比较均匀的场景,通过合理的分区策略,可以显著提高数据处理的速度和效率。
当单表数据量超过千万级别时,数据库的性能可能会受到影响,在这种情况下,分表是一个有效的解决方案,分表可以将一个大表分割成多个小表,每个小表包含的数据量更小,查询时需要处理的数据量也随之减少,从而提高查询效率,分表还可以并行处理查询请求,进一步提升数据处理能力。
视图、存储过程和触发器也是优化大数据量处理的有效工具,视图可以简化复杂的查询操作,避免重复编写相同的SQL代码;存储过程允许在数据库中直接处理数据,减少客户端与数据库之间的数据传输;触发器则可以自动执行预定义的操作,保持数据完整性和一致性。
数据库的备份和恢复策略也是数据量化管理不可忽视的一部分,定期备份可以防止数据丢失或损坏,确保数据的安全性和可靠性,用户和权限管理则可以控制对数据的访问,防止未授权访问或操作,保证数据的安全。
MySQL数据量的内容数据量化涉及到多个方面,包括合理选择数据类型、实施表分区、适时进行分表以及利用视图、存储过程和触发器等数据库对象来优化数据处理,这些策略和工具的有效运用,可以显著提高数据库的性能,支持企业的数据增长,满足不断变化的业务需求。
相关问答FAQs
Q1: 为什么单表数据量不能超过千万?
A1: 单表数据量超过千万会影响查询性能,大量的数据意味着检索数据时需要更多的时间和计算资源,导致查询响应时间变长,影响用户体验和系统性能。
Q2: 如何判断是否需要进行分表?
A2: 通常当单表数据量接近或超过系统的性能瓶颈时,就应该考虑分表,具体的指标包括查询响应时间显著增长,数据库服务器的CPU和内存使用率持续高位运行等。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/995280.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复