


爬虫IP查询失败或服务器错误是一个常见的问题,通常会对数据抓取任务产生重大影响,解决此类问题不仅需要技术知识,还需要对可能出现的错误类型和解决方法有所了解,以下是详细的分析和建议:
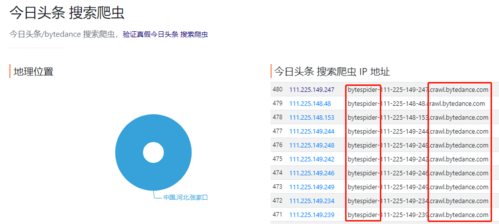

1、超时错误
原因分析:超时错误通常由网络延迟或服务器响应时间过长引起。
解决方法:增加请求的超时时间是常用对策,在Python的requests库中,可以通过设置timeout参数来调整超时时间。
2、连接错误
原因分析:网络不稳定或目标服务器无响应可能导致连接错误。
解决方法:检查网络连接,并确保目标服务器地址正确且在线。
3、拒绝服务
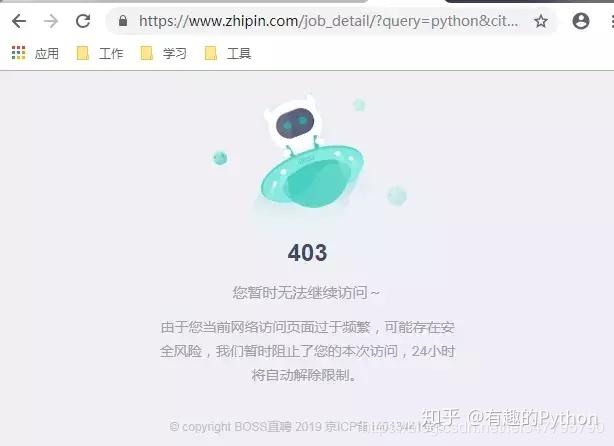
原因分析:服务器可能因请求频率过高而主动拒绝服务。
解决方法:控制请求频率,使用合理的时间间隔,并检查是否启用了防止拒绝服务的机制。
4、代理设置错误
原因分析:错误的代理设置或端口配置可能导致无法使用代理服务器。
解决方法:确认代理服务器的地址和端口设置正确,若必要,进行适当的配置更改。
5、代理服务器不可用
原因分析:代理服务器可能因离线、负载过高或被封禁而无法使用。
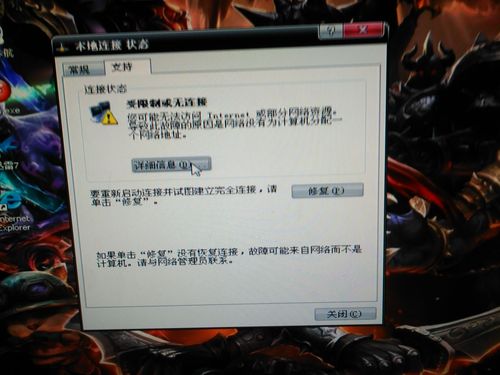
解决方法:更换代理服务器或选择其他可用的IP进行重试,监控代理服务器的状态,以确保稳定性和可用性。
6、IP黑名单限制
原因分析:使用的爬虫IP可能被目标网站列入黑名单,导致访问受限。
解决方法:联系代理供应商更换未被列入黑名单的IP,或者遵守目标网站的访问规则减少被封风险。
7、服务器过载
原因分析:服务器可能会因为过多的请求处理而变得过载。
解决方法:暂时降低请求频率,分散请求压力。
8、网站IP地址或域名解析错误
原因分析:网站的IP地址不正确或无法解析可能导致访问失败。
解决方法:使用WHOIS或host命令检查网站IP地址,必要时与域名注册商联系更新。
合理配置请求头,模拟浏览器行为可以减少被识别为爬虫的风险,使用Session维持会话,或在多个IP之间轮换,可以有效避免因单一IP过度请求而被封禁的问题。
结合上述信息,对于爬虫开发者而言,理解和应对IP查询失败或服务器错误是至关重要的,通过精心选择和配置代理服务器,遵循网站的抓取规则,优化请求策略,可以显著提高爬虫的稳定性和效率,保持与代理服务提供商的良好沟通,及时获取替代IP资源,也是确保爬虫持续运行的关键措施。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/993198.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复