



MapReduce是由Google提出的一种面向大规模数据集(大于1TB)的并行计算模型,它设计用于简化大数据集的处理工作,允许开发人员编写处理大量数据的代码,而无需关注集群的细节,本报告旨在深入解析MapReduce编程模式,并探讨其在大数据处理中的应用与影响。
起源与发展
Google在2003年的SOSP大会上首次提出了MapReduce的概念,随后于2004年在OSDI上发表了详细论文《MapReduce: Simplified Data Processing on Large Clusters》,这篇论文迅速引起了广泛关注,并成为大数据处理领域的经典之作。
编程模式
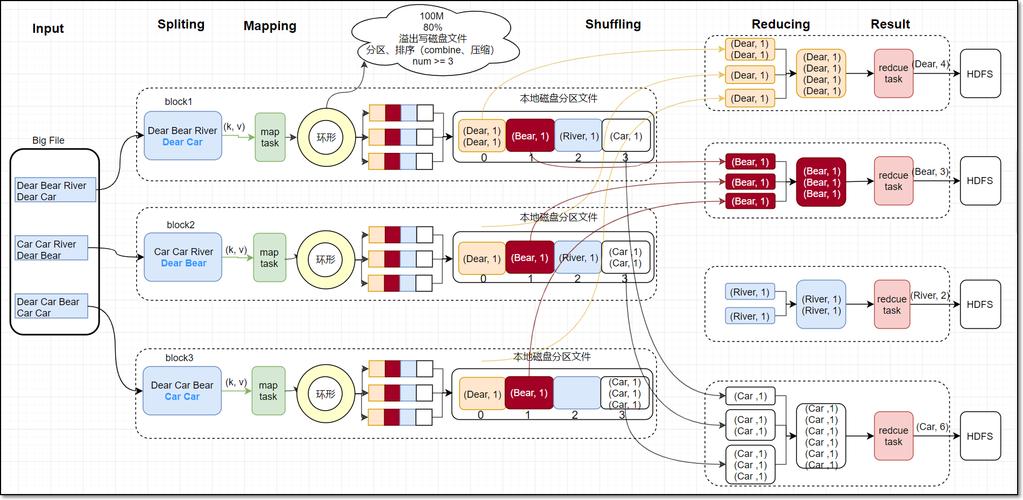
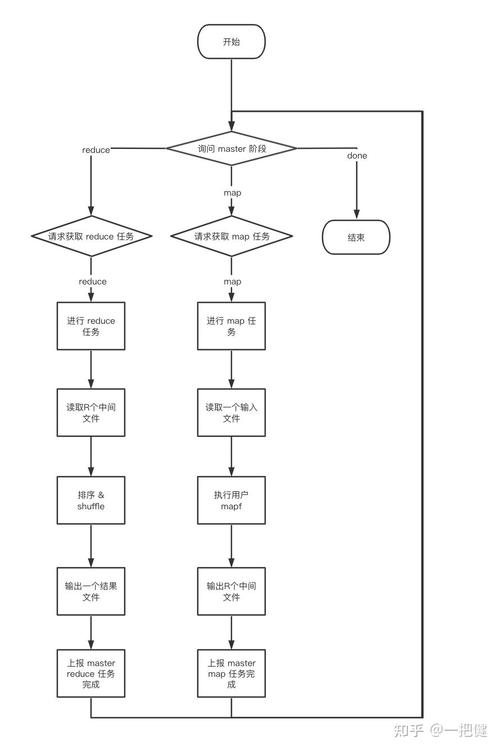
MapReduce的核心是“映射(Map)”和“归约(Reduce)”两个阶段,在映射阶段,系统将输入数据分割成独立的块,这些块由多个Map任务在集群的不同节点上并行处理,每个Map任务生成一组<键,值>对,作为中间结果,系统根据键对这些<键,值>对进行排序和分组,以确保所有具有相同键的值被发送到同一个Reduce任务,在归约阶段,每个Reduce任务负责处理一部分数据,并生成最终的结果。
应用场景
MapReduce广泛应用于各种需要处理和分析大量数据的领域,如互联网搜索索引构建、日志文件分析、机器学习数据预处理等,它的高效性和易用性使其成为企业和研究机构处理大数据的首选工具。
优势与局限
MapReduce的优势在于其简单性和可扩展性,编程人员只需关注Map和Reduce函数的逻辑,而无需处理并行计算、数据分发和故障恢复等复杂问题,MapReduce也存在局限性,如不适合低延迟和实时处理的需求,对于复杂的数据交互和多次迭代处理效率不高。
未来趋势
随着大数据技术的不断发展,MapReduce也在不断进化,新的计算模型如Apache Spark等提供了更高效的内存计算和迭代处理能力,但MapReduce依然是大数据处理的重要基础,MapReduce可能会与新兴技术融合,形成更加强大的数据处理解决方案。
MapReduce作为一种革命性的大数据处理模型,极大地推动了数据处理技术的发展,尽管面临着新的挑战和竞争,MapReduce的基本思想和应用仍将在大数据领域发挥重要作用。
相关问答FAQs:
Q1: MapReduce适用于哪些类型的数据处理?
A1: MapReduce特别适用于批量处理大量独立数据的情况,如日志分析、数据挖掘、文本处理等。
Q2: MapReduce与Apache Spark有何不同?
A2: Apache Spark提供了更优化的内存计算能力和更快的迭代处理速度,而MapReduce更适合处理大批量的数据,且在处理大规模非迭代任务时更为稳定和成熟,两者可以视具体需求选择使用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/992722.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复