


GROUP BY语句进行分组查询。如果你有一个名为students的表,并且你想要根据grade字段对其进行分组,你可以执行以下查询:,,“sql,SELECT grade, COUNT(*) ,FROM students ,GROUP BY grade;,“,,这将返回每个年级的学生数量。在MySQL数据库查询中,分组查询是一种常用的操作,它可以将具有相同特征的数据行集合在一起,从而使得数据分析、汇总和报表生成等工作变得更加高效,要深入理解MySQL中的分组查询,首先需要掌握其基本语法结构,了解如何通过聚合函数对数据进行统计计算,以及如何在实际场景中应用分组查询。


语法详解与结构
基本的MySQL分组查询语法包括SELECT,FROM,WHERE,GROUP BY和ORDER BY几个部分。SELECT语句用于指定查询的列,FROM语句指明要查询的表名,WHERE条件用于过滤记录,GROUP BY用于指定分组的列,而ORDER BY则用来对结果集排序。
聚合函数如COUNT(),SUM(),AVG(),MAX(),MIN()等,是实现数据统计的关键,它们能够在GROUP BY子句返回的每个分组上执行计算。SELECT column1, COUNT(column2) FROM table_name GROUP BY column1;这样的查询可以返回column1中每个不同值的column2计数。
实际应用场景
在实际应用中,分组查询广泛用于销售数据分析、网站访问统计、财务报表制作等领域,一个电商网站可能需要统计各个省份的订单数量,就可以使用分组查询来实现:
SELECT province, COUNT(*) FROM orders GROUP BY province;
这个查询将订单表(orders)按照省份(province)字段进行分组,并计算每个省份的订单数量。
高级技巧与优化
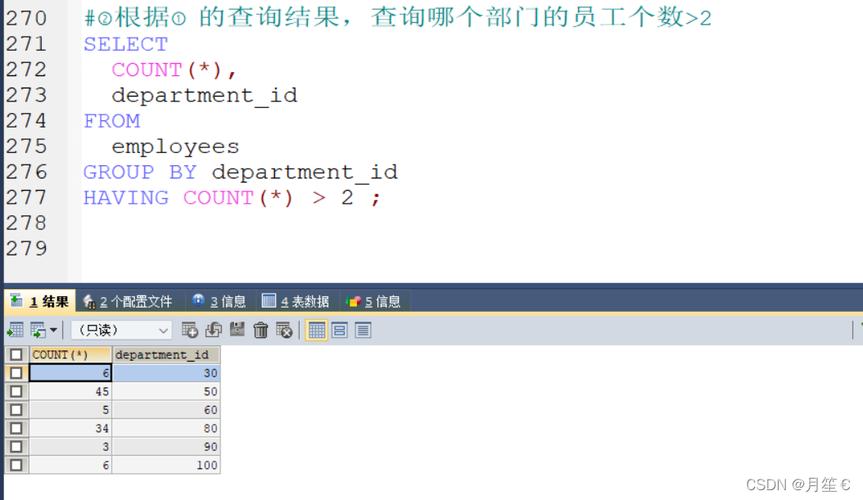
对于更复杂的统计分析任务,可以在分组查询中使用HAVING子句来筛选分组后的聚合结果,若要找出订单总数超过100的省份,可以使用以下查询:
SELECT province, COUNT(*) FROM orders GROUP BY province HAVING COUNT(*) > 100;
当数据量较大时,合理使用索引可以显著提高分组查询的性能。
相关FAQs
1. 分组查询中是否可以使用非聚合列?
可以,但非聚合列必须包含在GROUP BY子句中,否则可能产生不可预期的结果或数据库错误。
2. 如何对分组后的结果进行排序?
可以在查询末尾添加ORDER BY子句对分组结果进行排序,如按照聚合结果的数值大小、字母顺序等。

通过上述分析,我们可以看出MySQL分组查询不仅在语法上灵活多变,而且在处理数据聚合方面功能强大,无论是在日常的业务报表生成还是复杂的数据分析任务中,分组查询都是不可或缺的工具,掌握分组查询的使用,能够有效提升数据处理的效率和质量。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/992460.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复