


MapReduce单词统计是大数据处理框架Hadoop中非常经典的案例,主要用于文本处理,特别是统计大量数据中单词出现的频率,该程序分为两个主要阶段:Map阶段和Reduce阶段,具体操作步骤和逻辑如下:

1、准备输入数据
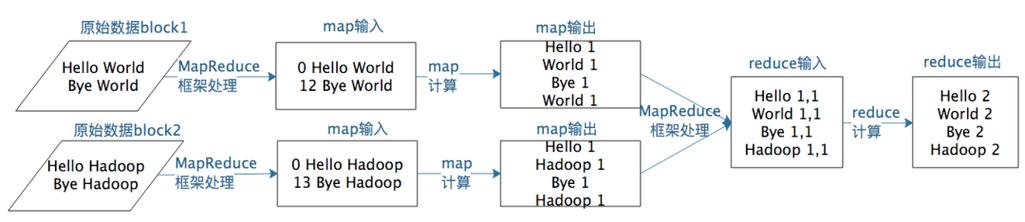
创建文件:首先在本地或HDFS上创建包含文本内容的文本文件,如word.txt文件,内容可以是"hello kdl. hello world. hello hadoop."等。
上传HDFS:使用Hadoop文件系统命令将文件上传到HDFS指定的目录中,如/wordcount/input目录。
2、Map阶段
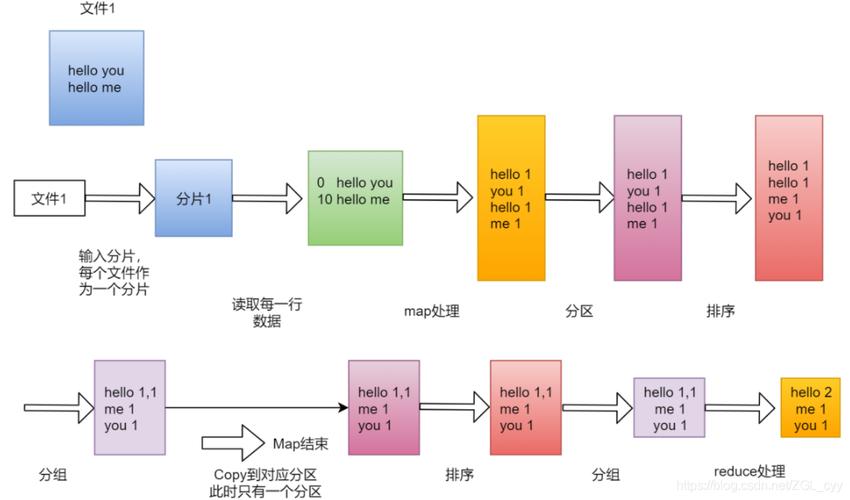
任务划分:Hadoop将输入数据划分为多个等长的输入分片(input split),每个分片通常对应一个map任务。
分词计数:每个map任务对其分片进行处理,分析每一行记录,将行内容分割成单词,并为每个单词计数(写入<word, 1>表示该单词出现一次)。
3、Shuffle阶段
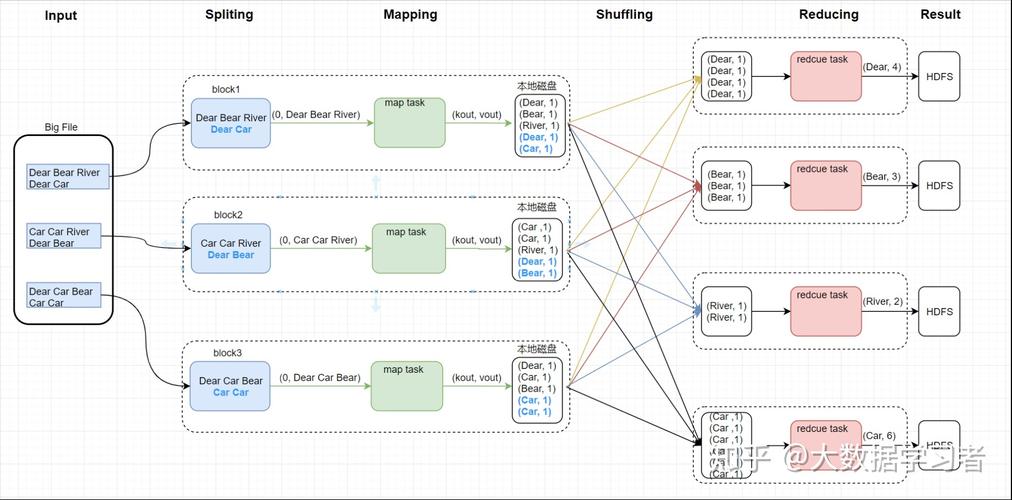
排序和传输:MapReduce框架会对所有输出的键值对进行排序,并将具有相同键的值传输给同一Reduce任务。
4、Reduce阶段
聚合计数:Reduce任务接收到所有分配给它的键及其对应的值列表,然后对这些值进行迭代求和,以汇总每个单词的总出现次数。
5、输出结果
存储结果:最终的单词计数结果通常会存储在HDFS上,以便进行进一步的处理或检索。
6、编程实践
编码Map函数:需实现Map函数,用于处理输入文档并将每行文本切分成单词,产生中间的<key, value>对,其中key是单词,value是该单词的出现频率。
编码Reduce函数:同样需要实现Reduce函数,它负责接收Map任务输出的中间结果,并汇总得到每个单词的总出现次数。
使用MapReduce进行单词统计不仅是学习Hadoop编程的入门案例,同时也展示了如何通过分布式计算处理大规模数据分析任务,掌握这一流程有助于理解和解决更复杂的数据处理问题,还需注意优化MapReduce作业的性能,例如合理设置Map和Reduce任务的数量,以及选择合适的数据类型和格式来提高运算效率和减少资源消耗。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/991073.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复