

在当今大数据处理领域,MapReduce框架是支撑批处理任务的基石之一,作为一个分布式计算框架,它允许将大规模数据处理任务分发到多个计算机节点上进行并行计算,以提高效率和计算性能,本文旨在深入分析MapReduce中的线程概念,探讨其在提升数据处理效率方面的作用,以及在实际编程实践中的应用。
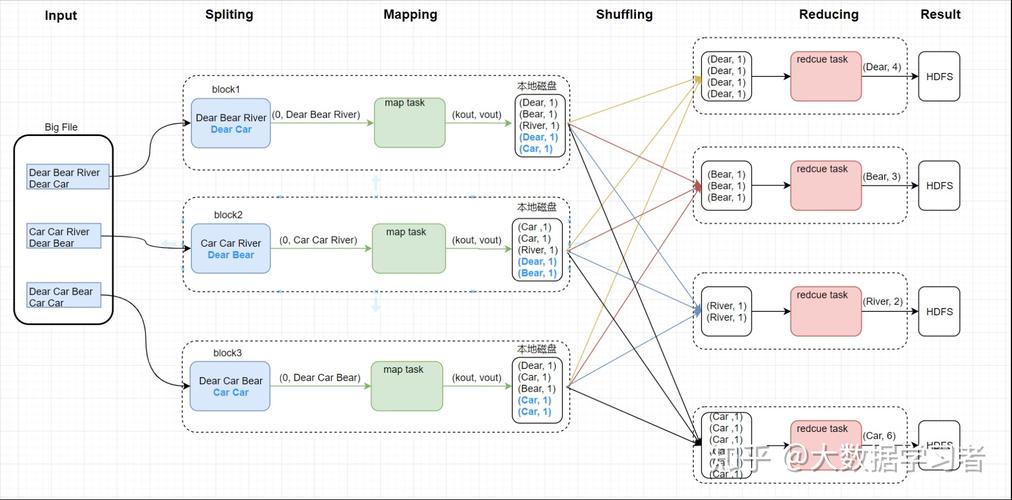

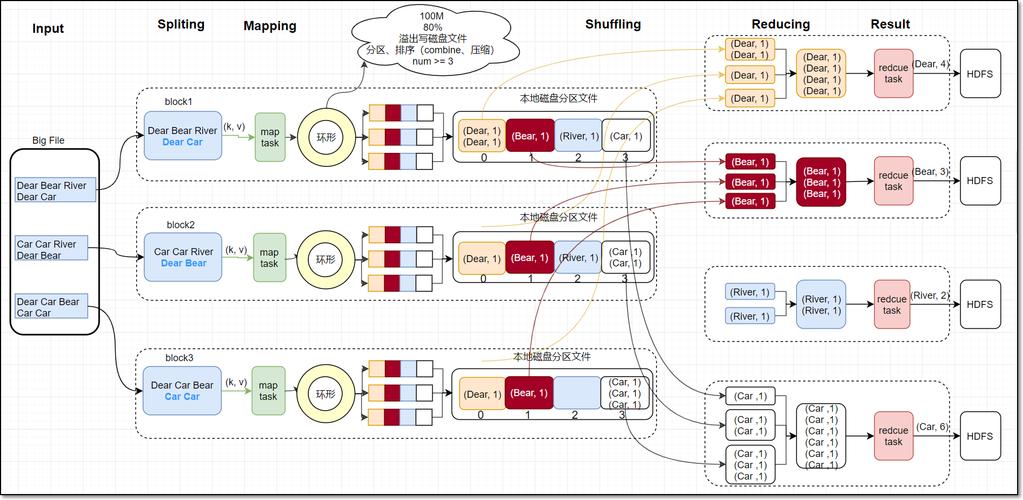
MapReduce模型的核心在于两个阶段:Map阶段和Reduce阶段,在Map阶段,系统会将输入数据分成多个数据块,每个数据块分别由一个Map任务进行处理;而在Reduce阶段,则是将Map阶段的输出结果进行汇总处理,生成最终的结果。
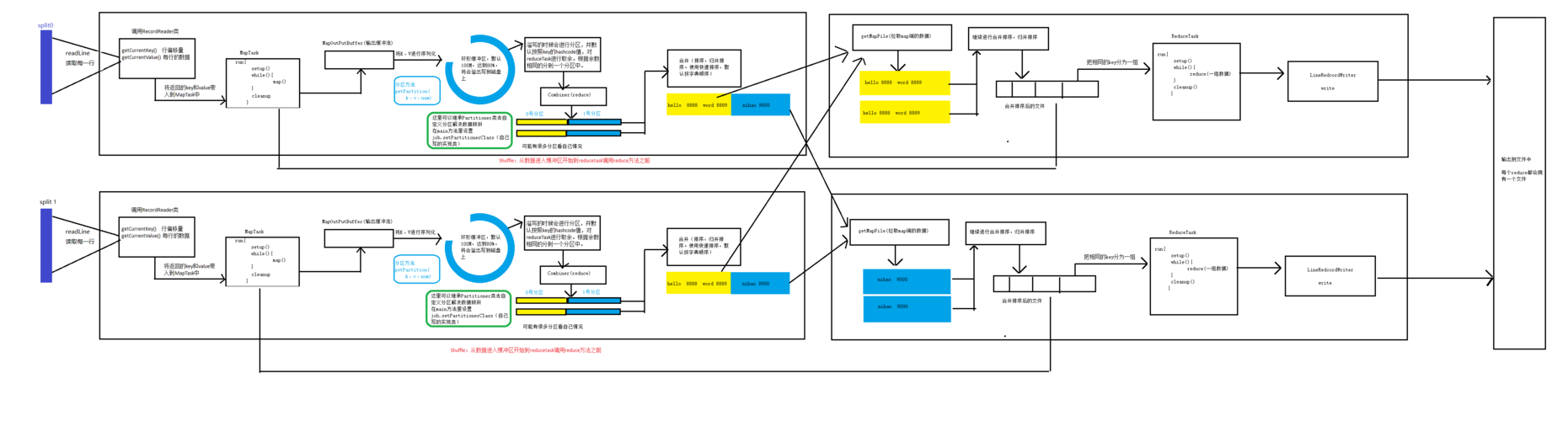
让我们详细了解Map阶段的线程应用,Map阶段的主要任务是将输入数据分割成独立的小块,然后并行处理每一块数据,在传统的单线程执行模式下,每个Map任务按顺序执行,这意味着必须等待前一个任务完成后才能开始下一个任务,在多线程环境下,可以同时启动多个Map任务,每个任务在一个独立的线程中运行,这样不仅加快了数据处理速度,还提高了系统资源的利用率,尤其是在多核处理器上运行时效果更为显著。
接下来是Reduce阶段的线程应用,在Reduce阶段,线程的使用同样可以优化性能,通过配置如mapreduce.reduce.shuffle.read.timeout参数,可以调整下载时间段的最大值,这有助于控制线程在拉取Map输出结果时的等待时间,从而更有效地管理网络资源和线程生命周期。
值得注意的是,MapReduce框架通常采用多进程模型运行,即每个Task运行在一个独立的JVM进程中,这虽然确保了任务间的隔离性和稳定性,但也限制了线程级并行性的利用,相比之下,如Spark等其他大数据处理框架采用了多线程模型,能更好地利用现代硬件架构的优势。
为了充分挖掘多线程在MapReduce中的潜力,开发者需要考虑以下关键因素:
1、资源管理:合理分配和调度计算资源,避免资源争用导致的性能瓶颈。
2、任务划分:合理划分Map和Reduce任务,确保各个任务负载均衡,避免个别任务成为性能瓶颈。
3、错误恢复:设计健壮的错误恢复机制,确保在任务失败时能够快速恢复,减少重复工作。
对于希望深入了解MapReduce多线程模型的开发者,可以通过创建分治任务线程池并实现特定计算任务(如计算斐波那契数列)来练习和理解线程在MapReduce中的应用,通过实际编码实践,可以更加深入地掌握线程管理、任务调度以及性能优化等方面的知识。
FAQs
Q1: 如何调整MapReduce中线程的超时时间?
A1: 可以通过调整参数mapreduce.reduce.shuffle.read.timeout的值来设定线程在读取Map输出时的超时时间,默认值为180000毫秒,根据集群环境和任务需求进行调整。
Q2: MapReduce使用多线程是否总是提高性能?
A2: 并非总是如此,多线程可以提高性能,但也可能因资源争用、任务划分不当或数据依赖性强等原因导致性能下降,需要根据实际情况仔细设计和调整。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/990753.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复