


MapReduce 中的 PUT 操作
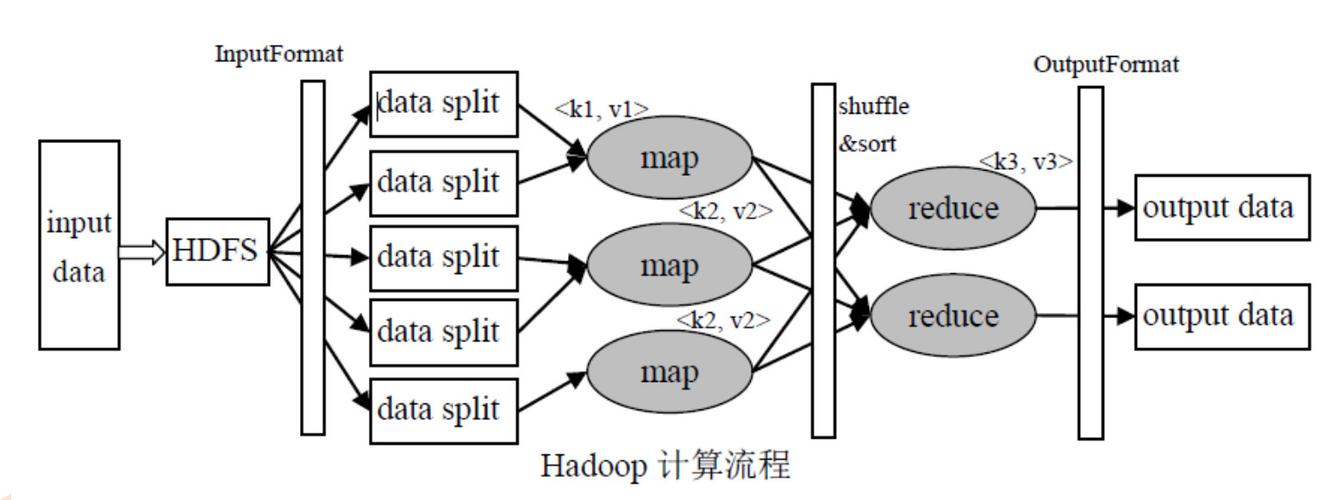

MapReduce 是一种编程模型,用于处理和生成大数据集,它包含两个主要阶段:Map 阶段和 Reduce 阶段,在这两个阶段之间,数据需要从 Map 任务传输到 Reduce 任务,这个过程通常涉及到数据的排序和混洗(shuffle),PUT 操作通常指的是将数据写入到分布式文件系统中,为 Reduce 阶段做准备。
Map 阶段的输出
在 Map 阶段,输入数据被分割成多个小数据块,每个数据块由一个 Map 任务处理,Map 任务会处理这些数据块并产生中间键值对(keyvalue pairs),这些中间结果通常需要写到磁盘上,以便后续的 Reduce 阶段可以访问它们。
Shuffle and Sort 阶段
在 Map 阶段完成后,产生的中间键值对需要经过 Shuffle and Sort 阶段,这个阶段包括对 Map 输出的结果进行分区(partition)、排序和可能的压缩,分区是为了确保具有相同键的所有值都会被发送到同一个 Reduce 任务,排序则是为了让 Reduce 阶段的处理更加高效。
PUT 上传操作
在 Shuffle and Sort 阶段后,Map 任务的输出需要上传到一个共享的文件系统或者直接传输给 Reduce 任务,这个上传过程可以被视为 PUT 操作,即将数据“放”到指定的位置供 Reduce 任务使用。
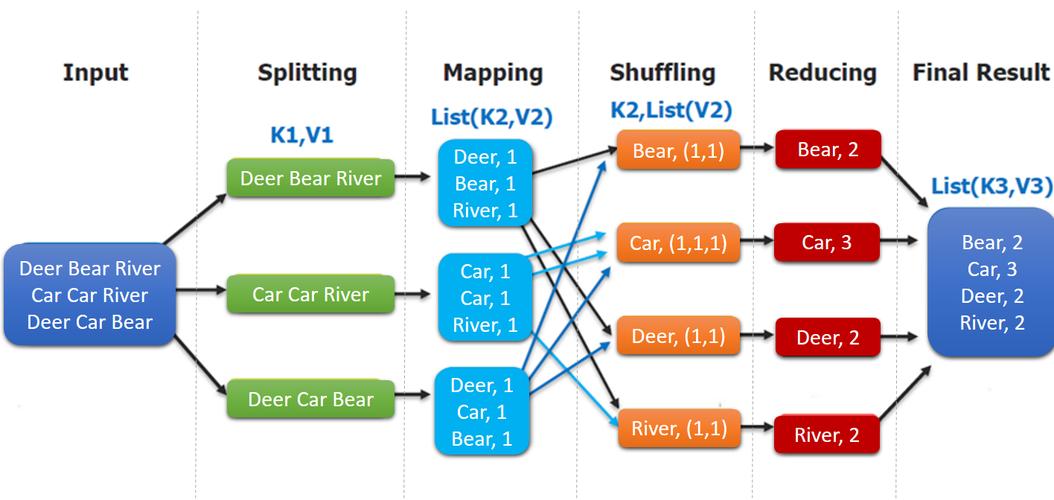
具体步骤如下:
1、分区:根据键的值,将 Map 输出的数据分配到不同的 Reduce 任务。
2、排序:对每个分区内的键值对进行排序,以确保键的顺序。
3、PUT 上传:将排序后的分区数据写入到分布式文件系统中的指定位置,或通过网络直接发送给对应的 Reduce 任务。
注意事项:
PUT 操作需要保证数据的可靠性,避免数据丢失。
需要考虑网络带宽和延迟,优化数据传输效率。

对于非常大的数据集,PUT 操作可能需要分批进行,以避免单个节点上的资源瓶颈。
相关问答 FAQs
Q1: MapReduce 中 PUT 操作是否会影响整体性能?
A1: 是的,PUT 操作在 MapReduce 中非常关键,因为它涉及到数据的传输,PUT 操作执行得不够高效,可能会导致数据传输缓慢,从而影响整体性能,优化数据传输机制和网络配置对于提高 MapReduce 作业的整体性能至关重要。
Q2: MapReduce 作业失败,PUT 上传的数据会怎样?
A2: MapReduce 作业在 PUT 操作之后失败,那么已经上传的数据可能会保留在分布式文件系统中,除非有自动的清理机制,在重新启动作业时,需要有策略来决定是重新执行失败的任务还是从上次成功的地方继续,这取决于具体的框架和配置,Hadoop 的 MapReduce 通常会提供重试机制和恢复功能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/990123.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复