


bash,hadoop jar.jar,`,,请将 、、 和 ` 替换为实际的值。在当今大数据时代,处理庞大的数据集已成为许多组织和研究机构日常操作的一部分,MapReduce,作为分布式系统上处理大数据集的编程模型,自2004年由Google提出以来,已广泛应用于各种数据处理任务中,下面将深入探讨如何启动和运行MapReduce程序,确保内容的准确性和全面性,并期望通过清晰的逻辑表达,使读者能够轻松理解这一复杂但强大的技术。
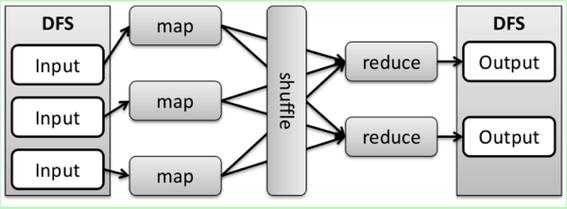
配置环境
要顺畅地运行MapReduce任务,首先需要配置好Hadoop环境,这包括设置Hadoop集群、Java环境以及必要的路径变量。
安装Java: 确保所有节点都安装了Java,并设置了JAVA_HOME,如搜索结果所示,可以通过在Linux系统中输入echo $JAVA_HOME命令来确认Java家园路径是否已正确设置。
配置Hadoop环境: 编辑hadoopenv.sh文件,确保JAVA_HOME变量指向正确的Java安装目录,这一步是启动所有Hadoop支持的MapReduce作业的基础。
部署Hadoop集群: 在完成环境配置后,部署Hadoop集群是下一步,这包括设置NameNode和DataNodes等核心组件,具体部署过程取决于选择的Hadoop版本和预期的集群规模。
编写MapReduce程序
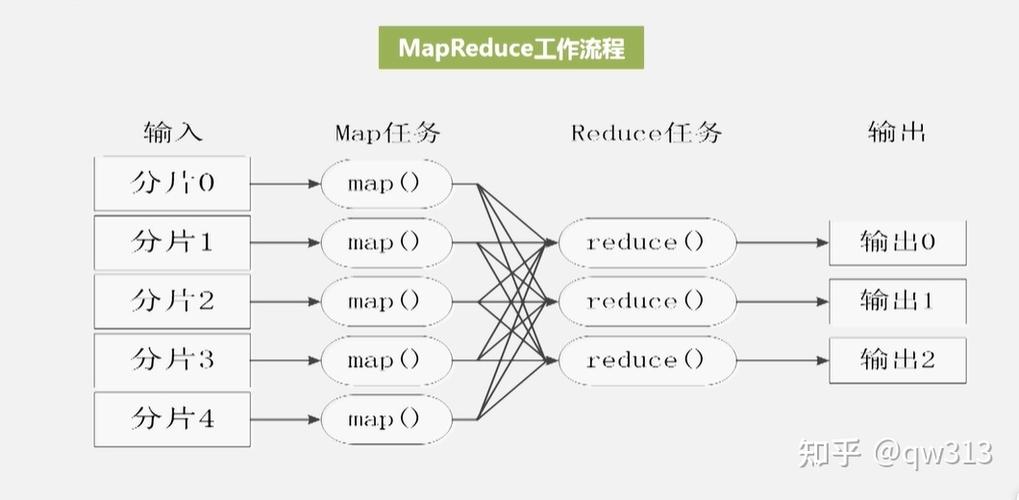
MapReduce程序主要由两部分组成:Map函数和Reduce函数,Map函数处理输入数据并生成中间键值对,而Reduce函数则对这些中间数据进行汇总。
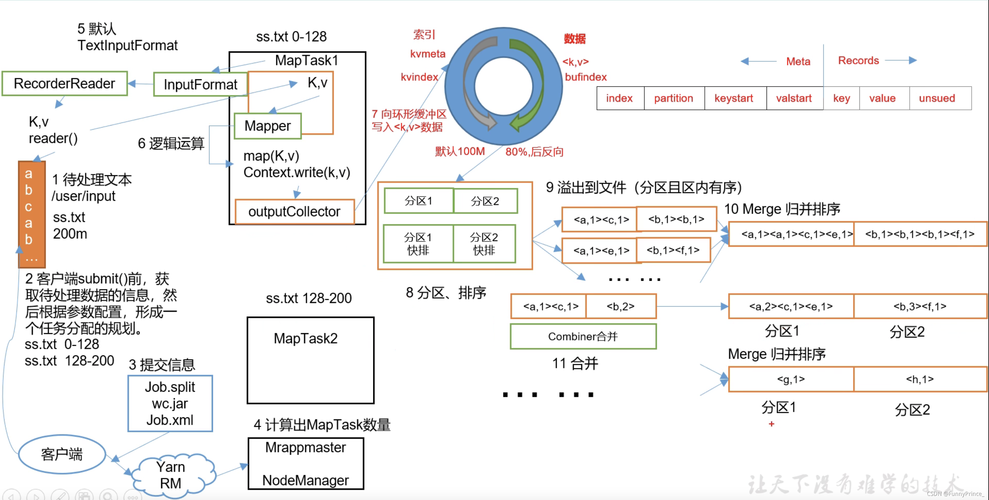
编写Map函数: 此函数需要对输入数据进行处理,生成一组中间键值对,这些键值对将被用于后续的Reduce阶段。
编写Reduce函数: 该函数接收Map函数生成的中间键值对,并根据键进行聚合,生成最终结果。
对于初学者来说,可以利用Hadoop提供的示例程序(如WordCount)开始学习如何编写MapReduce代码。
启动和监控MapReduce任务
在Hadoop集群上运行MapReduce任务涉及多个步骤,从提交任务到监控其执行状态。
提交任务: 使用Hadoop客户端提交编写好的MapReduce作业,命令通常如下:
“`bash
hadoop jar mymapreducejob.jar [myDriverClass] [input location] [output location]
“`
监控任务: 使用Hadoop提供的工具,如Web界面或命令行工具,监控任务的状态和性能,可以查看每个任务的进度,以及Mapper和Reducer的执行情况。
优化与故障排除
为保证MapReduce作业高效运行,需要考虑一些优化策略和故障排除方法。
合理设置Reducers的数量: 根据数据集的大小和结构来调整Reducers的数量,可以显著影响作业的执行时间。
内存管理: 优化Map和Reduce函数中的内存使用,避免内存溢出错误。
启动和运行MapReduce程序是一个涉及多个步骤的过程,从环境配置到代码编写,再到任务提交和监控,每一个步骤都需要细致的关注才能确保作业的成功执行,不断优化和调整是提高作业效率的关键。
FAQs
Q1: MapReduce作业运行缓慢,我该如何检查问题所在?
A1: 检查集群的资源利用率,包括CPU和内存使用情况,查看作业的日志文件,寻找可能的错误或警告信息,考虑是否有必要调整Reducers的数量或优化代码逻辑。
Q2: 如何在Hadoop集群上进行故障排除?
A2: 使用Hadoop提供的工具,如hdfs dfsadmin报告和Web界面来检查HDFS的状态,对于MapReduce作业,可以使用mradmin命令来获取作业的详细信息,检查硬件问题,如网络连接和磁盘健康状况也是必要的。
MapReduce虽然是一个强大的工具,但其成功启动和运行需要对Hadoop生态系统有深入的理解以及严格的步骤控制,通过上述指南,用户可以更好地准备环境,编写和调试MapReduce程序,最终实现高效的数据处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/989740.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复