


在当今大数据时代,处理海量数据集已成为企业和科研机构面临的一大挑战,MapReduce模型自2004年由Google提出以来,因其高效的数据处理能力而被广泛应用于数据分析和数据挖掘领域,本文将深入探讨MapReduce的进阶实战技巧,帮助读者更好地理解和应用这一技术。


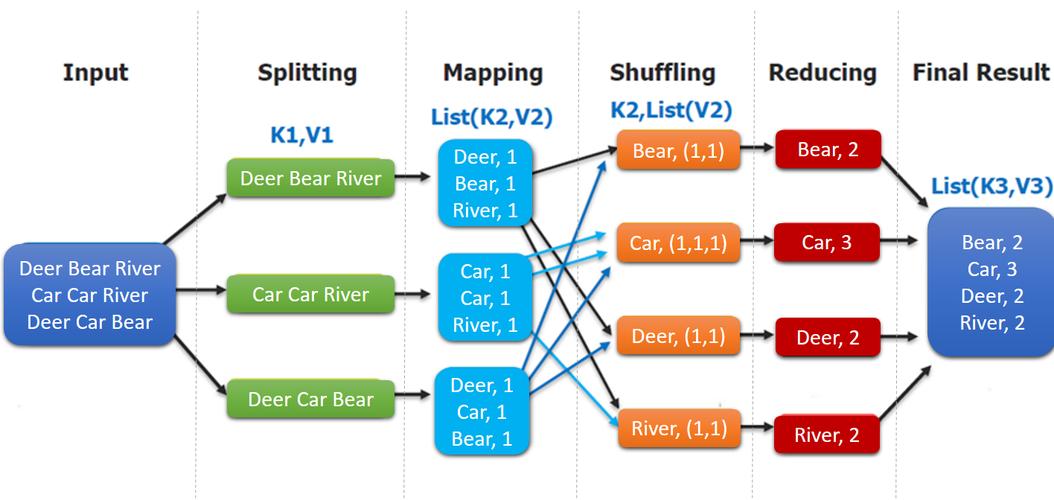
MapReduce的基本概念和工作原理是其应用的基础,MapReduce分为两个阶段:Map阶段和Reduce阶段,在Map阶段,程序将输入数据分割成小块,然后并行处理这些数据块;而在Reduce阶段,则将Map阶段的输出整合起来,得到最终结果。
进阶技巧一:Combiner优化
在处理大量数据时,合理使用Combiner可以显著提高MapReduce作业的性能,Combiner是一种在Mapper端进行的本地reduce操作,它通过减少Mapper与Reducer之间的数据传输量来优化性能,如表1所示,开启Combiner后,网络传输的数据量明显减少,从而提高了整体的处理速度。
表1: Combiner优化效果示意
| 场景 | 未使用Combiner | 使用Combiner |
| 数据传输量 | 高 | 低 |
| 处理速度 | 慢 | 快 |
进阶技巧二:自定义Partitioner
MapReduce默认的Partitioner可能不适用于所有场景,通过实现自定义Partitioner,可以更灵活地控制数据如何被分发到各个Reducer,如果某个特定键的数据量非常大,可以将其独立分配到一个Reducer上,避免数据倾斜问题。
进阶技巧三:优化I/O操作
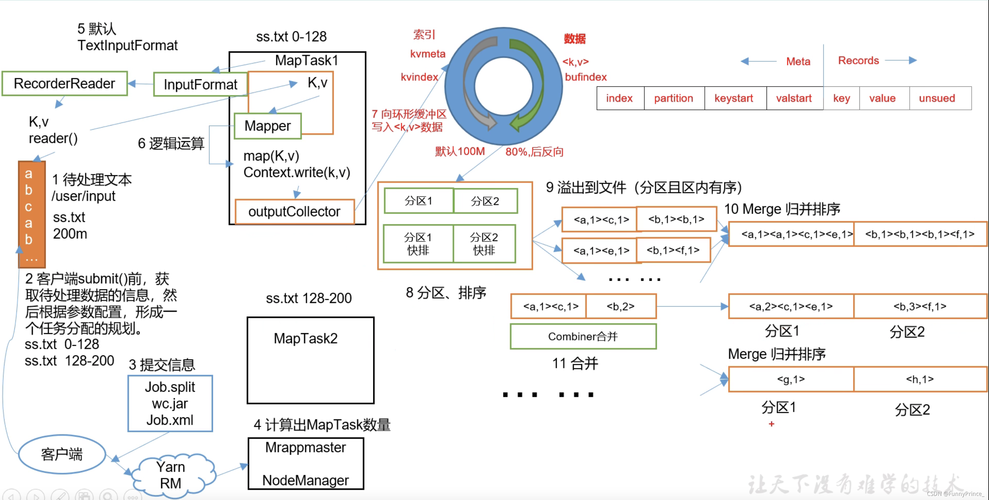
MapReduce作业中,大量的时间可能消耗在读写磁盘操作上,优化I/O操作的方法包括压缩中间数据和最终输出,以及合理设置缓冲区大小,通过压缩,虽然增加了CPU的负担,但减少了磁盘I/O和网络传输的负载,通常能获得更好的性能。
进阶技巧四:选择合适的数据格式
数据的序列化和反序列化在MapReduce中非常关键,选择一种高效的数据格式,如Avro、Parquet或ORC,可以加速数据处理过程,因为这些格式通常具有更好的压缩比和读写效率。
进阶技巧五:调优内存和CPU使用
对于计算密集型任务,可以通过增加JVM的堆大小或调整MapReduce的内存配置来提升性能,合理设置Map和Reduce任务的数量,以匹配集群的CPU核心数,也是提高资源利用率的有效方法。
便是MapReduce进阶实战中的一些关键技巧,通过这些方法,可以显著提高MapReduce作业的性能和效率。
相关问答FAQs
Q1: 为什么在某些情况下使用Combiner反而会降低性能?
A1: 使用Combiner确实可以减少数据传输量,但同时也会增加Mapper端的计算负担,如果Mapper的任务本身计算量不大,而数据量又不是特别大的情况下,引入Combiner可能会因为额外的计算开销而得不偿失,是否使用Combiner应根据具体作业的特征来决定。
Q2: 自定义Partitioner是否有潜在的风险?
A2: 自定义Partitioner确实可以提供更灵活的数据处理方式,但也可能导致数据分布不均,从而引起某些Reducer过载而其他Reducer空闲的情况,在实现自定义Partitioner时,需要仔细考虑数据的分布情况,以避免出现负载不均衡的问题。
MapReduce作为一个强大的分布式计算框架,通过适当的优化和调整,可以有效地处理大规模数据集,无论是通过使用Combiner减少数据传输,还是通过自定义Partitioner优化数据分布,或是通过调整内存和CPU资源提高资源利用率,这些进阶技巧都是提升MapReduce性能的关键,希望本文能为读者在实际应用MapReduce时提供一定的帮助和指导。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/989294.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复