




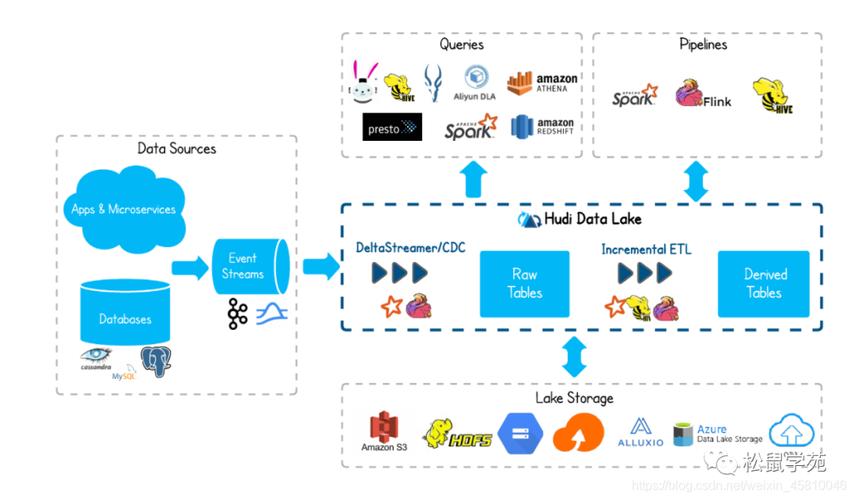
Hudi(Upstream Data Ingestion)是一个高效的大数据处理框架,旨在解决大规模数据摄入和快速数据查询的问题,用户在操作Hudi作业时可能会遇到作业长时间处于BOOTING(启动中)状态,这会严重影响数据处理效率,本文将深入探讨此问题的原因及提供一系列解决方案,帮助用户有效缓解或彻底解决这一问题。
在Hudi作业执行过程中,数据摄入、查询优化和系统资源管理是影响作业状态的三个核心因素,长时间BOOTING状态通常与这几个方面的问题密切相关:
1、数据摄入瓶颈:当数据源产生数据的速度快于Hudi处理速度时,会导致作业积压,从而使得作业长时间处于启动状态,这种情形常见于流数据处理场景,需要通过优化数据摄入设置来解决问题。
2、查询优化不足:复杂的查询操作或者不恰当的索引策略可能导致查询效率低下,进而影响作业的启动和执行,针对这一点,优化查询逻辑和索引设置是关键。
3、系统资源竞争:Hudi作业可能与其他并发作业竞争计算和存储资源,资源限制可能导致作业无法获得足够的计算资源而长时间处于BOOTING状态,合理配置资源和调度策略是解决这一问题的有效途径。
针对上述原因,以下是几个具体的解决方案:
1、优化数据摄入设置:可以通过调整Hudi的写入配置,如批量大小(batch size)和写入模式(如同步写入或异步写入),来提升数据处理速度,合理设置数据分区和预整合(precombing)策略也能有效减少数据摄入的延迟。
2、优化查询逻辑和索引:简化查询语句,避免不必要的复杂连接和计算,建立有效的索引可以显著提高查询速度,减少数据扫描范围,使用Bloom Filter索引可以加速非主键列的查询。
3、合理配置资源和调度策略:通过工具进行资源调度,确保Hudi作业能够获得充足的资源,可以考虑将数据高峰期的作业调度到资源相对空闲的时段执行,避免与其他重作业竞争资源。
归纳而言,解决Hudi作业长时间处于BOOTING状态的问题需要从数据摄入、查询优化以及系统资源管理三个方面入手,通过实施上述建议,不仅可以优化Hodi的运行效率,还可以保证数据处理的稳定性和可靠性。
相关问答FAQs:
Q1: 如何确定Hudi作业的资源需求?
A1: 可以通过历史运行数据分析出作业的峰值资源消耗,结合集群的整体资源状况来设定每个作业的资源配额。
Q2: 如何进一步提升Hudi作业的查询性能?
A2: 除了优化查询逻辑和增加索引外,定期进行数据文件的合并(compaction)可以减少查询时需要访问的文件数量,从而提高查询性能。
面对Hudi作业长时间处于BOOTING状态的问题,采取合适的策略和措施至关重要,通过上述分析和解决方案的实施,可以显著改善Hudi的处理效率,确保数据作业的平稳和高效运行。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/989274.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复