


python,from mrjob.job import MRJob,,class MRWordFrequencyCount(MRJob):,, def mapper(self, _, line):, words = line.split(), for word in words:, yield (word, 1),, def reducer(self, word, counts):, yield (word, sum(counts)),,if __name__ == '__main__':, MRWordFrequencyCount.run(),“MapReduce是一种在Hadoop平台上广泛使用的分布式计算模型,它能够处理大规模数据集,该模型将复杂的计算任务分为两个阶段:Map阶段和Reduce阶段,从而简化了编程模型,使得开发者可以专注于业务逻辑的实现而不是分布式计算的细节,我们将通过一个基本的词汇统计实例来详细解析MapReduce代码。
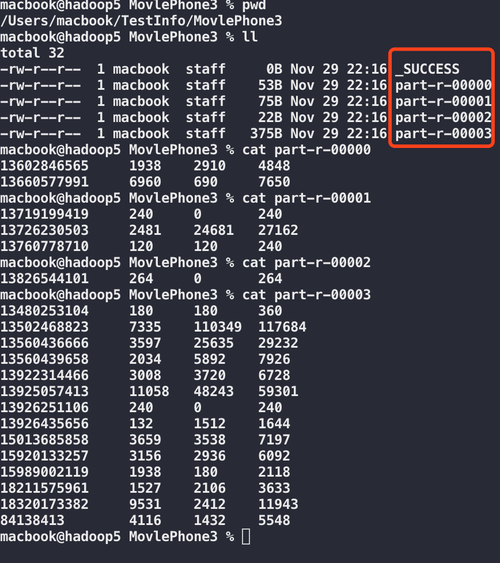

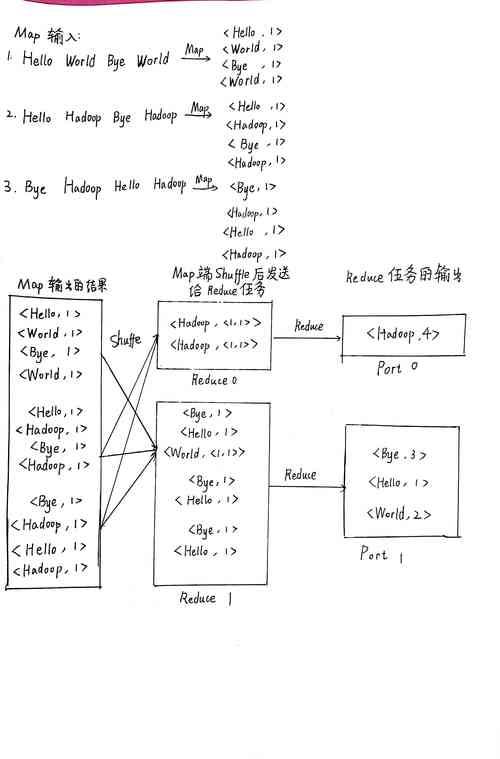
我们来看Map部分,在MapReduce框架中,Map阶段的任务是读取输入数据,并转换为键值对(keyvalue pair),在这个词汇统计的例子中,Map函数会读取文本文件的每一行,并将每一行的内容拆分为单词,然后以单词作为键(key),出现的次数作为值(value)输出。
public static class WordCountMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
public void map(Object key, Text value, Context context) throws IOException, InterruptedException {
StringTokenizer itr = new StringTokenizer(value.toString());
while (itr.hasMoreTokens()) {
word.set(itr.nextToken());
context.write(word, one);
}
}
} 上述代码段定义了一个名为WordCountMapper的类,它继承自Hadoop框架中的Mapper类,这个类重写了map方法,该方法负责处理输入的数据片段,并将其转化为键值对,在此过程中,每个单词被标记为一个单独的键,而其对应的值为1,表示这个单词出现了一次。
接下来是Reduce部分,在MapReduce框架中,Reduce阶段的任务是接收来自Map阶段的输出,并进行合并操作,在词汇统计的例子中,Reduce函数会对所有相同的键(即同一个单词)进行迭代,累加它们的值(即单词的出现次数),得到每个单词的总出现次数。
public static class WordCountReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
} 这段代码定义了一个名为WordCountReducer的类,它同样继承自Hadoop框架中的Reducer类,这个类重写了reduce方法,用于处理来自Mapper的所有相同键的值,对于每一个键,它都会遍历所有相关的值,并计算它们的总和,然后将结果写回到上下文中,这样,每个单词的总出现次数就被成功计算出来。
为了更好地理解MapReduce程序的运行机制,我们还需要注意以下几点:
1、输入输出格式:MapReduce作业的输入和输出数据格式需要事先定义好,通常使用Hadoop的序列化机制来处理数据的读和写。
2、数据分区:Map阶段的输出会根据一定的规则(通常是哈希或范围分区)分发到各个Reducer上,以确保具有相同键的值最终会被同一个Reducer处理。
3、并行处理:Map和Reduce两个阶段可以并行执行,这样可以大大提高处理速度,Hadoop框架还提供了容错机制,确保在硬件故障的情况下数据不会丢失,计算可以重新执行。
针对于MapReduce编程模型,以下是一些常见问题及其解答:
Q1: MapReduce适用于什么样的数据处理场景?
A1: MapReduce特别适用于批量处理大量非结构化或半结构化数据的场景,大数据分析、日志处理、推荐系统的基础数据计算等。
Q2: 如何优化MapReduce作业的性能?
A2: 优化MapReduce作业性能的方法包括但不限于:合理设置数据分区以平衡Reducer的负载、选择合适的数据序列化方式以减少I/O开销、以及配置合适的内存和磁盘缓冲区大小以优化数据的读写效率。
归纳而言,MapReduce作为一种强大的分布式计算模型,通过将复杂计算分解为子任务,并在多台计算机上并行处理这些子任务,极大地简化了编程复杂度并提高了处理效率,通过本文提供的词汇统计实例,我们不仅学习了具体的编程技巧,还理解了MapReduce框架的核心原理和工作流程。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/989200.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复