


在数据库管理与数据分析中,随机查询是一种常见的需求,尤其是在MySQL数据库中,用户经常需要从大量数据中随机抽取样本,用于测试、分析或演示,随机森林回归作为一种强大的机器学习方法,常被用于预测和建模任务,因其集成多个决策树而闻名,提高了模型的准确率和泛化能力,本文将深入探讨MySQL中的随机查询技巧和随机森林回归的概念及应用。


MySQL中的随机查询:
1. RAND()函数:
使用RAND()函数是实现随机查询的最直观方法,用户可以在SQL查询中使用ORDER BY RAND()来实现数据的随机排序,从员工表中随机选取一条记录,可以使用如下语句:
SELECT * FROM employees ORDER BY RAND() LIMIT 1;
这种方法简单易用,但主要适用于数据量不大的情况,对于大型数据库,此方法可能因需要对所有行计算RAND()值而效率较低。
2. 使用JOIN子查询:
为提高查询效率,可以使用JOIN子查询的方法,这种方法通过将表与自身进行连接,利用RAND()函数产生的随机数作为连接条件,从而避免了对整个表使用RAND()函数。

示例查询如下:
SELECT e1.* FROM employees e1 JOIN (SELECT FLOOR(RAND() * (SELECT COUNT(*) FROM employees)) AS idx) e2
此方法在处理大数据集时表现更好,速度通常比直接使用RAND()函数要快。
3. 利用变量:
另一种技术是使用用户定义的变量来存储随机生成的ID,然后根据这个ID来选择随机记录,这可以在不使用RAND()的情况下完成随机选择,尤其适用于id字段连续且均匀分布的场景。
示例代码如下:
SET @id := FLOOR(RAND() * (SELECT MAX(id) FROM employees)); SELECT * FROM employees WHERE id >= @id LIMIT 1;
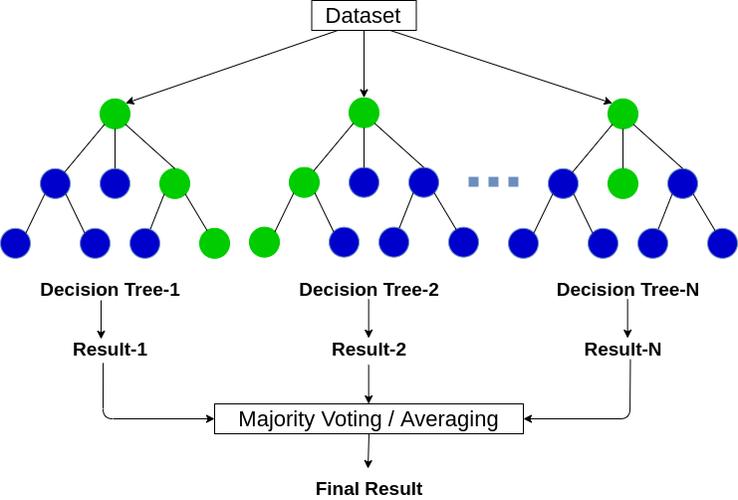
随机森林回归解析:
1. 原理和结构:
随机森林是一个包含多个决策树的分类器,它通过集成学习的原理—即结合多个模型以提高总体性能—来工作,在回归任务中,随机森林回归器采用相同的原理,但输出是实数值而非类别标签。
在训练阶段,每个决策树都通过从原始数据集中随机选择一部分样本和特征来构建,这种随机性减少了模型之间的相关性,提高了整体的泛化性能。
2. 参数调优与应用:
随机森林回归的性能很大程度上依赖于其参数设置,如树的数量、最大深度、最小样本数等,合理调整这些参数可以有效避免过拟合,并提高预测的准确性。
在实际应用中,随机森林回归可用于各种场景,如销量预测、股价估计等,在电商领域,通过历史销售数据训练随机森林回归模型,可以较为准确地预测未来产品的销量。
无论是在数据库管理还是机器学习领域,随机查询和随机森林回归都是非常实用的方法,它们各有特点和应用场景,理解并掌握这些技术,可以帮助更好地处理数据分析和预测任务,正确的方法选择和参数调整,是确保高效和准确结果的关键。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/988636.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复