


CONVERT()函数将中文字符转换为拼音,然后使用ORDER BY进行排序。假设有一个名为students的表,其中有一个名为name的中文字段,可以按照以下方式进行排序:,,“sql,SELECT * FROM students ORDER BY CONVERT(name USING gbk) COLLATE gbk_chinese_ci;,“在MySQL中实现中文排序,涉及到一系列的设置和操作,以确保数据不仅在存储时准确无误,而且在查询时也能高效地返回正确结果,由于汉字的特殊性,直接使用默认的拉丁字母排序规则往往不能达到预期的效果,因此需要采用特定的方法来实现正确的中文排序,本文将详细介绍MySQL中文排序的方法,包括选择合适的字符集和排序规则、自定义排序规则和使用拼音索引等技术。

选择合适的字符集和排序规则
在创建数据库和表时,选择合适的字符集和排序规则是确保中文数据正确性的第一步,字符集定义了文字和符号的编码方式,而排序规则则确定了这些字符如何进行比较和排序,对于中文来说,通常推荐使用utf8mb4字符集,因为它能够支持更多的Unicode字符,包括扩展的汉字和表情符号,配合utf8mb4使用的最佳排序规则是utf8mb4_general_ci或utf8mb4_unicode_ci,这两者的主要区别在于它们对字符大小写的敏感程度以及国际字符的处理方式。
通过在创建表时指定这些设置,可以避免因字符编码不一致而导致的数据问题,在创建表时可以这样指定:
CREATE TABLE my_table (
id INT UNSIGNED AUTO_INCREMENT,
name VARCHAR(100) NOT NULL,
PRIMARY KEY (id)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_general_ci; 这样的设置确保了表中的中文数据能够被正确地存储和检索。
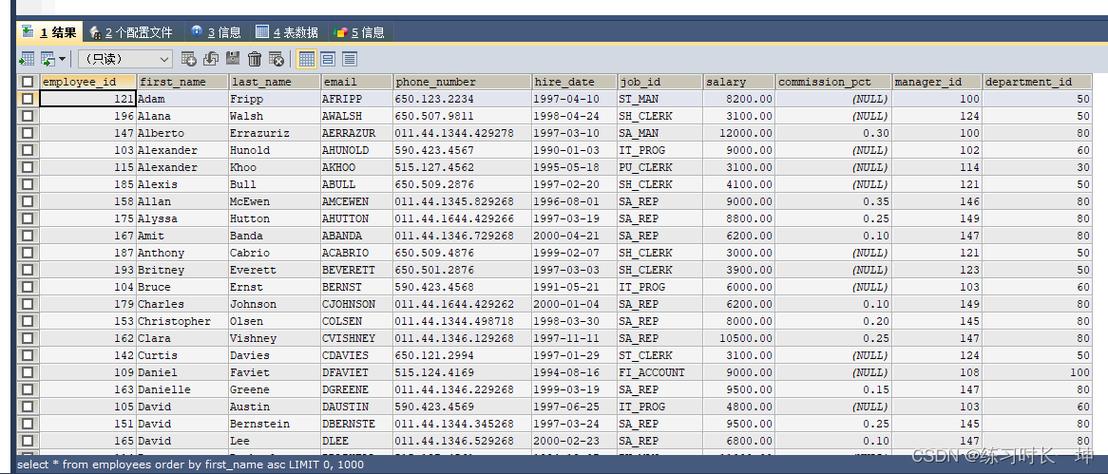
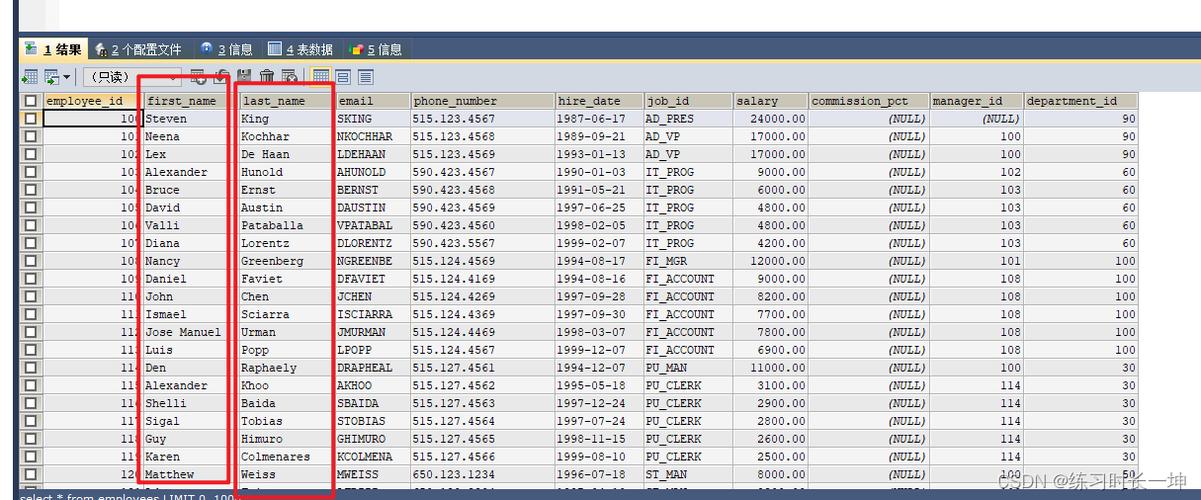
使用ORDER BY子句进行排序
在MySQL中,ORDER BY子句是用来指定按照哪个字段的值进行排序的关键工具,对于中文文本,直接使用ORDER BY可能会得到不准确的结果,因为默认的排序规则可能不适用于汉字,要改进这一点,可以通过设定COLLATE子句来改变排序行为,若要按照中文的字典顺序对某个字段进行排序,可以使用如下SQL命令:
SELECT * FROM my_table ORDER BY my_column COLLATE utf8mb4_general_ci;
这里,COLLATE utf8mb4_general_ci明确指定了使用一种适合中文排序的校对规则,这种方法简单易行,适用于大多数需要对中文进行简单排序的场景。
自定义排序规则
对于更复杂的中文排序需求,如需要根据汉语拼音或笔划数进行排序,可以使用自定义的排序规则,这通常涉及到创建一个函数,该函数能够返回用于排序的键值,可以创建一个根据汉语拼音排序的函数,然后在查询中使用这个函数来生成排序的键值,这种方法更加灵活,但实现起来也更为复杂,需要有一定的SQL和编程知识。
使用拼音索引
另一种解决中文排序问题的方法是通过建立拼音索引,这意味着除了存储原始的中文数据外,还需要存储每个汉字的拼音,可以在拼音字段上创建索引,以便更快地进行排序和搜索,这种方法需要额外的存储空间,并且在写入数据时会增加计算拼音的开销,但可以显著提高排序查询的效率。
相关FAQs
Q1: 在MySQL中实现中文排序最常见的问题是什么?
A1: 最常见的问题是默认的字符集和排序规则不适合中文字符,导致排序结果不正确或出现乱码,解决这一问题的基本方法是选择适当的字符集(如utf8mb4)和排序规则(如utf8mb4_general_ci)。
Q2: 如果我想根据中文的笔画顺序进行排序,应该如何操作?
A2: 要根据笔画顺序进行排序,你可能需要使用第三方库或者自定义函数来获取每个汉字的笔画数,并据此进行排序,这通常比基于拼音的排序更为复杂,因为需要处理汉字的拆分和笔画数的计算,在实际操作中,这可能涉及到较为复杂的SQL编程和额外的数据处理工作。
通过以上方法,可以有效地解决MySQL中中文排序的问题,确保数据的正确性和查询的效率,无论是通过选择合适的字符集和排序规则,还是使用更高级的技术如自定义排序规则或拼音索引,都可以根据具体的应用场景和需求来决定最合适的解决方案。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/985179.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复