

在DEDECMS中进行内容采集时,一个关键步骤是编写过滤规则,这涉及到对采集内容的处理,确保所得到的数据是干净、准确并且符合需求的,下面将深入探讨如何在DEDECMS中编写有效的过滤规则。


过滤规则的基本概念
过滤规则在DEDECMS采集系统中扮演着至关重要的角色,它们帮助用户从大量杂乱的数据中提取出有用信息,同时清除掉不需要的部分,如广告链接、多余的空格或HTML标签,通过精确的过滤规则,可以提高数据采集的质量与效率。
正则表达式的应用
在DEDECMS的采集过程中,正则表达式是编写过滤规则的核心工具,它能够匹配和替换文本中的特定模式,非常适用于处理标题中的多余空格、去除来源作者中的链接等场景,使用{dede:trim} 标签可以有效去除标题中的空格,使得采集回来的内容更加整洁。
过滤规则的编写步骤
1、明确目标:确定你希望采集哪些内容,以及需要过滤掉哪些元素。
2、:检查原始网页的HTML结构,识别所需数据的包围标签或特定的文本模式。
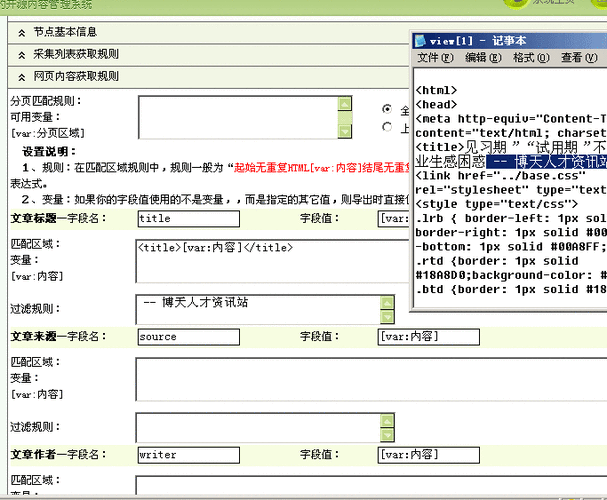
3、编写正则表达式:根据分析结果,编写匹配所需数据的正则表达式,同时写出用于剔除无用信息的表达式。
4、测试和调整:在DEDECMS中应用这些规则,并进行测试,根据测试结果反复调整正则表达式,直到达到满意的采集效果。
高级过滤技术
对于更复杂的采集需求,可能需要用到更高级的过滤技术,如:
条件过滤:针对具有特定属性或满足某些条件的文本进行过滤。
批量替换:当遇到大量相似格式的数据需要替换或删除时,可以利用正则表达式进行批量处理。
数据验证:对采集到的数据进行格式校验,保证其符合预设的标准或格式。
常见问题及解决策略
在采集过程中可能会遇到各种问题,如采集内容的格式不一致、出现了未预料的字符或标签等,这时需要回到过滤规则的编写阶段,重新审视并优化正则表达式。
问题一:采集的内容中包含大量无用的HTML标签怎么办?
解决方案:利用正则表达式匹配HTML标签并将其移除,或使用DEDECMS提供的strip_tags功能进行过滤。
问题二:如何处理采集数据中出现的特殊字符?
解决方案:根据需要剔除的特殊字符编写对应的正则表达式进行过滤,例如剔除电话号码、邮箱地址等敏感信息。
相关FAQs
1、Q: DEDECMS采集系统支持哪些类型的过滤规则?
A: DEDECMS采集系统主要支持基于正则表达式的文本匹配与替换规则,允许用户自定义规则以适应不同的采集需求。
2、Q: 如何优化DEDECMS采集系统的过滤规则以提高采集精度?
A: 优化方法包括确保正则表达式的准确性、定期更新规则以适应源内容的变化、以及利用测试反馈不断调整规则。
DEDECMS采集教程中的过滤规则编写是一个需要细致操作的过程,理解并运用正则表达式的强大功能,结合对采集目标的清晰认识,可以显著提高数据处理的效率和质量,通过不断实践与调整,用户能够掌握这一技能,从而在各种采集任务中发挥重要作用。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/983836.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复