


网络爬虫是互联网信息检索的重要工具,而Web服务器则是提供网页内容的基础设施,两者在互联网上扮演着互补的角色。


网络爬虫和Web服务器虽然在功能上有所不同,但它们都是互联网的重要组成部分,网络爬虫依赖于Web服务器提供的内容进行信息收集和处理,而Web服务器则通过与网络爬虫的交互,使自己服务的内容得到更广泛的传播和利用,接下来将详细介绍网络爬虫和它与Web服务器的关系:
1、网络爬虫的定义与功能
概念:网络爬虫,也称为网络蜘蛛或网络机器人,是一种自动访问互联网并获取页面信息的程序。
功能:它们按照预设的规则自动化地浏览网络中的信息,这些规则被称为网络爬虫算法。
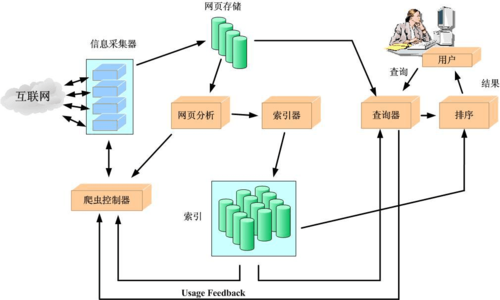
应用场景:搜索引擎如百度,利用其网络爬虫“百度蜘蛛”来爬取和收录互联网上的信息,以供用户检索。
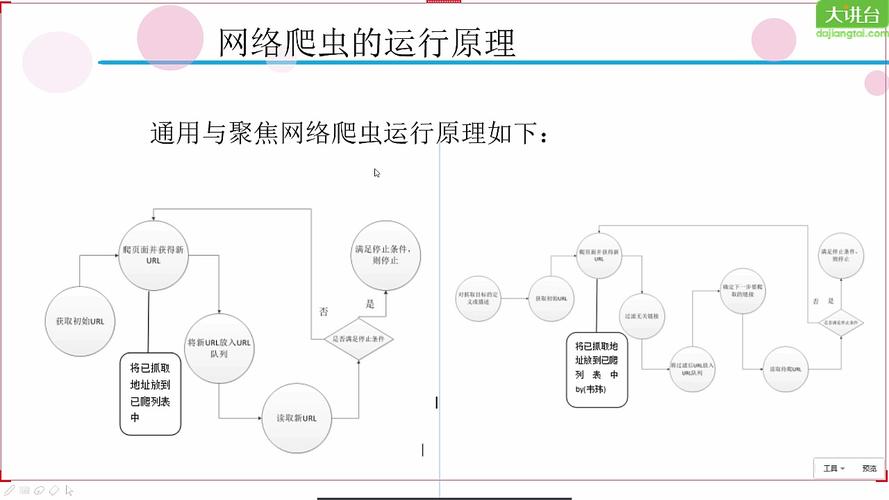
工作方式:网络爬虫通常从一个初始URL集合开始,跟随链接不断发现新的URL,这个过程叫做爬取。
2、Web服务器的定义与功能
概念:Web服务器是存储、处理并响应HTTP请求以提供网页内容给客户端的计算机系统或软件程序。
功能:接收来自客户端的请求,并根据请求返回相应的网站内容。
常见类型:包括Nginx、Apache、Tomcat、IIS等企业级Web服务器,它们各有特点,如Nginx以高性能和稳定性著称,而Caddy则提供了自动HTTPS功能和高度可配置性。
3、Web服务器与网络爬虫的互动关系
内容提供者:Web服务器是网络爬虫获取信息的来源,它提供了网络爬虫运行的基础数据。
访问频率与限制:为了保证服务器的正常运行和减轻负载,Web服务器可能会对网络爬虫的访问频率设定限制。
爬虫识别:合理的网络爬虫会标识自己,例如通过UserAgent告诉Web服务器自己是爬虫程序,方便服务器区分不同类型的请求者。
反爬机制:一些Web服务器会采用反爬措施,如验证码、IP封禁等,来防止恶意的网络爬虫爬取数据。
SEO优化:为了提高搜索引擎的排名,网站开发者会针对网络爬虫的工作原理进行SEO优化,使内容更容易被爬虫抓取和索引。
数据索引:网络爬虫爬取的数据通常会被索引和缓存,以便快速展示给用户,这是搜索引擎工作的核心环节。
协议遵循:网络爬虫在遵守Robots协议等规范的同时,Web服务器也可以通过这些协议指导爬虫的行为。
了解以上内容后,还可以进一步考虑一些与Web服务器和网络爬虫相关的额外信息:
Web服务器的性能对于网络爬虫的工作效率有直接影响,如果服务器响应慢或者不稳定,会影响爬虫的爬取速度和数据获取的稳定性。
网站的robots.txt文件定义了网络爬虫可以访问的页面范围,这对于爬虫来说是一种必须遵守的规则。
动态网站的内容是通过运行服务器端的代码即时生成的,这对网络爬虫提出了更高的要求,需要能够处理和解析脚本生成的内容。
由于网络爬虫的活动可能对Web服务器产生负担,善意的网络爬虫设计者会合理安排爬虫工作的时间和频率,避免对网站造成过大的压力。
随着技术的发展,越来越多的网站采取了反爬虫技术,如封IP、验证码等,这要求网络爬虫不断进化,采用更加智能的方式来应对。
Web服务器和网络爬虫之间存在着密切且复杂的关系,Web服务器为网络爬虫提供了生存和工作的空间,而网络爬虫则为服务器上的信息传播提供了有力的支持,它们之间的相互作用不仅影响着信息的流动和索引,也塑造了人们获取信息的方式。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/982036.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复