


Memcached作为一个广泛使用的高性能分布式内存缓存系统,对于提升应用性能具有重要作用,监控Memcached的关键指标是确保其正常运行并及时发现潜在问题的重要手段,本文将深入探讨Memcached的监控指标及其重要性,同时提供相关的监控实践建议。
理解Memcached的基础运行状态是监控的起点,启动状态是一个基本而关键的指标,它显示了Memcached实例是否在正常运行,如果Memcached服务停止,虽然系统的其他部分可能仍能通过访问底层数据库继续运作,但这种状况会导致系统运行效率明显下降,实时监控Memcached的启动状态,可以帮助管理员快速响应服务停机或重启的情况。
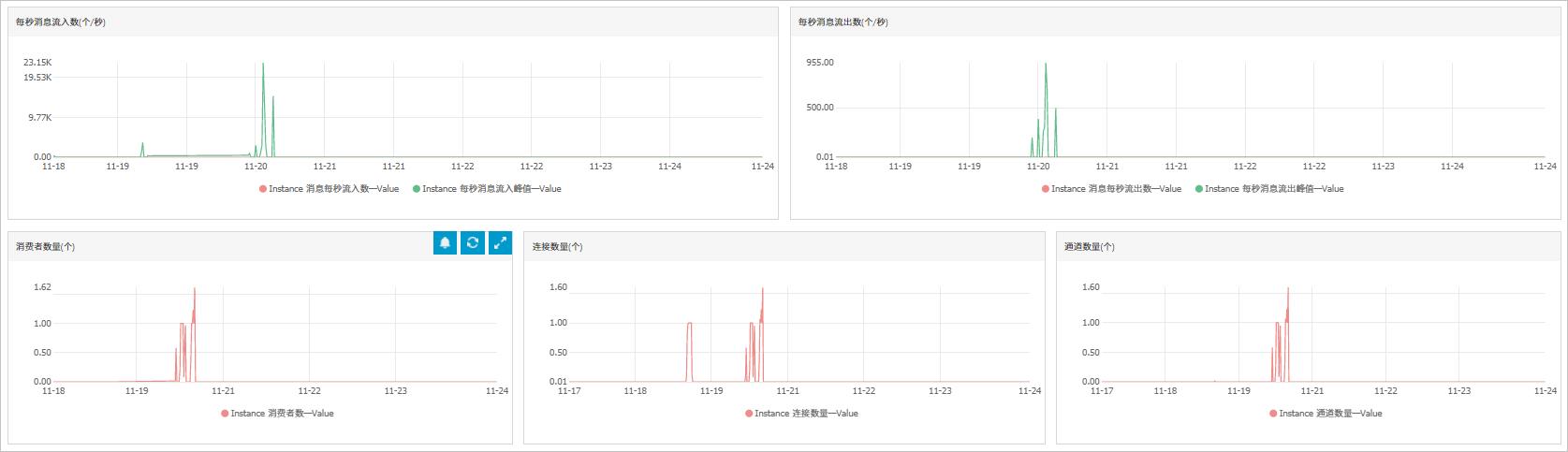
从资源使用情况的角度进行监控也至关重要,这包括内存使用量、CPU占用率和存储引擎的运行状态等,这些指标直接反映了Memcached服务的负载情况和资源分配的合理性,过高的内存使用可能暗示着缓存命中率高,但也可能导致资源竞争,影响其他服务的正常运行。
另一个重要的监控维度是性能指标,如请求速率、缓存命中率和往返时间等,这些指标帮助管理员评估Memcached服务的有效性和效率,高速的请求处理和高的缓存命中率通常意味着良好的性能,而长时间的数据处理延迟则可能需要进一步优化或扩容,具体如下表:
| 性能指标 | 说明 | 重要性 |
| 请求速率 | 单位时间内处理的数据请求次数 | 高请求速率可能指示高负载 |
| 缓存命中率 | 成功从缓存中获取数据请求的比例 | 高命中率表明缓存配置得当,效率更高 |
| 往返时间 | 完成数据请求所需的平均时间 | 较短的时间表示更快的响应速度 |
了解各种指标的特点和意义后,可以采用一些工具来实现对这些指标的监控,Prometheus是一个流行的选择,它通过Exporter的方式收集Memcached的运行数据,并提供了与Grafana集成的方案,使得监控数据的可视化变得简单直观,使用Prometheus监控Memcached涉及几个关键步骤,包括安装配置Memcached exporter、在Prometheus中配置scrape目标以及在Grafana中创建仪表板展示监控数据。
实际操作中,选择合适的监控工具并配置合理的报警阈值,能够在问题初期就发现并解决问题,从而保证Memcached服务的稳定性和高性能,定期的监控数据分析还可以帮助管理员更好地理解系统行为,指导未来的系统优化和资源规划。
为了更全面地掌握Memcached的监控要点,以下FAQs环节提供两个常见问题的答案:
FAQs
1. 如何确定Memcached的内存使用上限?
答案:Memcached的内存使用上限一般根据服务器的总内存和Memcached的角色来设定,一种常见的做法是预留一部分内存给操作系统和其他应用,剩余的内存分配给Memcached,具体数值没有固定标准,需要根据实际情况调整。
2. Memcached监控中响应时间突然增加是什么原因?
答案:响应时间的增加可能是由于多种因素导致的,包括但不限于网络延迟、服务器负载增加、内存不足导致的频繁换页,或是Memcached配置不当等,需要结合其他监控指标和日志信息,进行综合分析来确定具体原因。
通过对Memcached的关键监控指标进行持续追踪和分析,可以有效保障Memcached服务的稳定运行,并在出现问题时迅速作出反应,确保整个应用的高性能运行。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/981914.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复