


在Hadoop的HDFS架构中,NameNode扮演着核心角色,负责管理文件系统的元数据和协调客户端对文件的访问,EditLog是用于记录文件系统所有更改操作的重要日志文件,其连续性对于NameNode的正常启动至关重要,在实际操作中,由于各种异常情况,如断电、磁盘满或网络问题等,可能导致EditLog不连续,进而影响NameNode的启动,本文将深入分析MySQL数据库不连续与EditLog不连续导致NameNode启动失败的原因,并提出相应的解决方案。
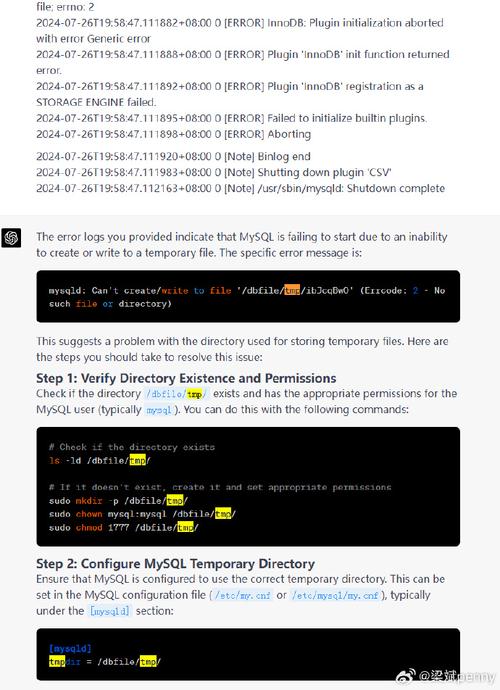

了解EditLog不连续的原因至关重要,在JournalNode节点发生断电、数据目录磁盘占满或网络异常的情况下,会导致JournalNode上的EditLog出现不连续现象,这种情况下重启NameNode时,会因无法正常读取EditLog而导致启动失败,NameNode的数据目录下可能会积累大量的edits_*文件,这些文件长时间未被清理,也会增加NameNode启动时的加载负担,延长启动时间。
针对上述问题,有几个步骤可以帮助解决EditLog不连续导致的NameNode启动失败:
1、检查启动日志:确认是否因数据丢失导致的启动失败问题,通过查看NameNode的启动日志可以快速定位问题所在。
2、恢复备份数据:利用SecondaryNameNode的备份数据进行恢复,SecondaryNameNode会定期保存EditLog和文件系统元数据的检查点,这些信息可以用来恢复丢失的数据。
3、同步JournalNode:确保JournalNode集群中的所有节点都能够正常通信并保持数据的一致性,使用hdfs zkfc formatZK命令来格式化ZooKeeper,然后重新启动JournalNode服务。
4、清理旧EditLog文件:定期清理NameNode数据目录下的旧edits_*文件,可以减少NameNode启动时的加载时间,提高启动效率。
5、优化存储配置:避免数据目录磁盘满的问题,可以通过扩展磁盘空间或优化存储配置来解决,合理配置JournalNode节点的副本数量,可以提高EditLog的可靠性和容错能力。
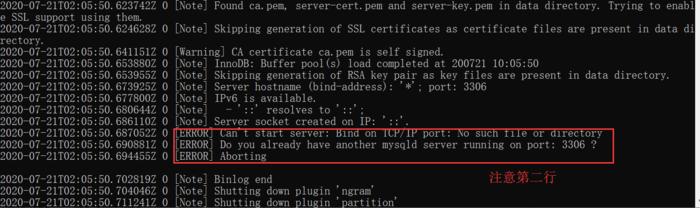
通过上述步骤,可以有效地解决因EditLog不连续导致的NameNode启动失败问题,在实施过程中,还需要注意以下几点:
在进行任何操作前,备份当前的数据和配置文件,以防数据丢失。
确保操作人员具有足够的权限执行相关命令和修改配置文件。
在生产环境中操作前,最好先在测试环境中验证解决方案的有效性。
面对MySQL数据库不连续与EditLog不连续导致NameNode启动失败的问题,通过检查启动日志、恢复备份数据、同步JournalNode、清理旧EditLog文件以及优化存储配置等步骤,可以有效地解决问题,注意备份数据、权限控制和测试验证的重要性,以确保数据的安全性和操作的顺利进行。
FAQs
Q1: NameNode启动失败有哪些常见原因?
A1: NameNode启动失败的常见原因包括EditLog不连续、数据目录磁盘满、网络异常、旧的edits_*文件积累过多等,这些问题都可能导致NameNode无法正常加载必要的启动信息。
Q2: 如何预防NameNode启动失败?
A2: 预防NameNode启动失败的措施包括定期清理旧EditLog文件、优化存储配置以避免磁盘满、确保JournalNode集群的高可用性和数据的一致性、定期备份SecondaryNameNode的数据等,通过这些措施,可以减少启动失败的风险,保证HDFS的稳定性和可靠性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/980113.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复