


在数字化时代,数据库是存储和管理数据的核心,尤其是MySQL这样的关系型数据库管理系统,由于其开放源代码的特性、高性能及易用性,被广泛应用于不同的业务场景中,随着数据量的不断增长,如何高效地读取大量数据库中的数据成为了一个重要议题,下面将深入探讨多种读取MySQL中大量数据的策略及其最佳实践,从而确保数据处理的高效与可靠。
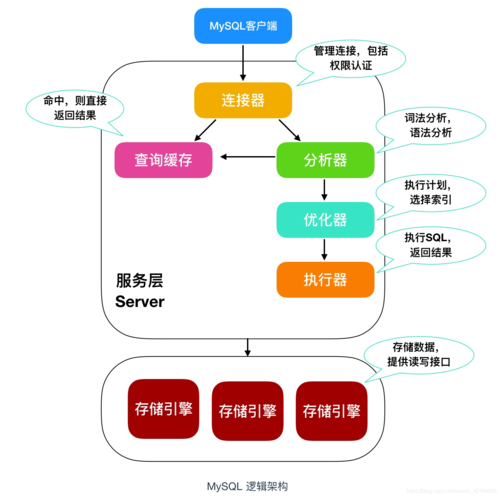

理解大型数据集的读取基本策略是基础,当涉及到大量数据的读取时,一次性加载所有数据到内存中显然是不现实的,这会导致内存溢出或程序崩溃,分批处理数据成为一种有效的策略,具体而言,可以采用限制查询结果集的大小,即利用SQL语句中的LIMIT和OFFSET子句来实现数据的分页读取,每次查询只获取一定数量的行记录,处理完成后,再获取下一批数据。
通过优化查询来提升数据读取速度也是关键,优化查询主要可以从以下几个方面进行:一是仅选择需要的列,避免使用SELECT;二是利用索引来加速查询过程;三是避免在列上使用函数或复杂的运算,这些都可能导致索引失效;四是使用EXPLAIN命令来分析查询计划,找出可能的性能瓶颈。
对于读取后的数据操作,使用高效的数据处理方法同样重要,在Python中,当读取大型数据表时,可以使用数据库游标作为迭代器逐行读取数据,这种方法可以在保持代码简洁的同时,有效控制内存占用。
了解一些高级技巧和工具的使用也不容忽视,在某些情况下,可能需要借助专门的数据库管理工具或平台来进行特殊操作,以腾讯云数据库MySQL为例,该平台提供了分钟级别的数据库部署和弹性扩展功能,使得大数据的处理变得更加自动化和高效,这类工具不仅提供了用户友好的管理界面,还优化了底层的数据读写机制,大大提高了处理大数据集的能力。
在处理大数据量的时候,还需要注意一些额外的因素,比如网络的延迟、服务器的性能以及并发访问的控制等,这些都可能影响到数据读取的效率,合理配置服务器资源,优化网络环境,以及控制并发数量,都是确保高效读取数据的重要环节。
有效地从MySQL数据库中读取大量数据,需要综合考虑查询策略的优化、数据处理方法的选择、以及利用先进的数据库管理工具等多方面因素,通过实施这些策略和技巧,可以显著提高处理大数据集的效率和可靠性。
针对这一话题,还可以进一步探讨至少两个相关的常见问题:
1、如何选择合适的批量大小进行数据分页读取?
2、在进行大数据量读取时,如何有效监控并优化查询性能?
回答:
1、批量大小:合适的批量大小取决于多个因素,包括系统的内存容量、网络延迟以及数据库的性能,建议从几千到几万行的范围内开始测试,逐步调整以找到最佳的批量大小。
2、性能监控与优化:使用像是EXPLAIN的SQL命令来分析查询计划是一个好的起点,数据库性能监控工具可以帮助实时监控查询性能,识别慢查询并进行优化。
高效读取MySQL中的大量数据要求对数据库查询进行精确控制和优化,同时需要合理利用现代数据库管理和数据处理工具,通过上述策略的实施,可以确保在处理大规模数据集时的效率和稳定性,满足不同业务场景下对数据处理的需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/979869.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复