


MapReduce实现二次排序
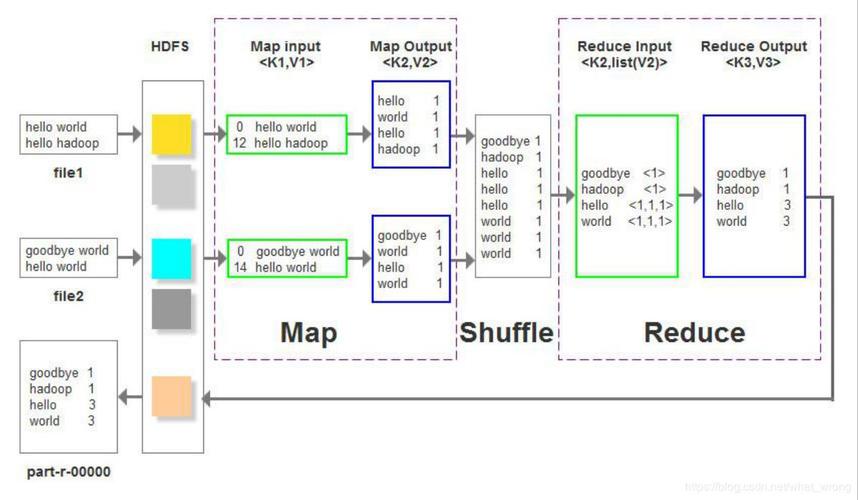

MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对,在Reduce阶段,所有具有相同键的值被组合在一起进行处理。
1. 问题描述
假设我们有一个包含学生信息的数据集,每个学生有姓名、年龄和成绩三个属性,我们希望按照成绩降序排列,如果成绩相同,则按照年龄升序排列。
2. 解决方案
为了实现这个需求,我们可以使用MapReduce框架进行两次排序,我们根据成绩对学生进行排序;对于成绩相同的学生,我们再根据年龄进行排序。
2.1 Map阶段
在Map阶段,我们将学生的姓名作为键,将年龄和成绩作为值输出,这样,我们可以确保所有具有相同成绩的学生都在同一个键下。
def map(student):
name = student['name']
age = student['age']
score = student['score']
return (score, age), (name,) 2.2 Shuffle阶段
Shuffle阶段会将所有具有相同键(即成绩和年龄)的键值对分组在一起,这样,我们就可以确保所有具有相同成绩的学生都在一个组中。
2.3 Sort阶段
Sort阶段会根据键值对中的键进行排序,由于我们的键是一个元组(成绩,年龄),所以MapReduce框架会首先根据成绩进行排序,然后在成绩相同时根据年龄进行排序。
2.4 Reduce阶段
在Reduce阶段,我们将每个组的学生姓名连接起来,并输出结果,因为我们已经按照成绩和年龄进行了排序,所以最终的结果就是按照成绩降序、年龄升序排列的学生列表。
def reduce(key, values):
names = [value[0] for value in values]
return key, names 3. 示例代码

以下是一个简单的Python代码示例,展示了如何使用MapReduce框架实现二次排序。
from functools import reduce
输入数据
students = [
{'name': 'Alice', 'age': 20, 'score': 95},
{'name': 'Bob', 'age': 21, 'score': 95},
{'name': 'Charlie', 'age': 19, 'score': 90},
{'name': 'David', 'age': 22, 'score': 85},
{'name': 'Eva', 'age': 20, 'score': 95}
]
Map阶段
mapped_data = list(map(lambda student: ((student['score'], student['age']), (student['name'],)), students))
Shuffle和Sort阶段(由MapReduce框架自动完成)
Reduce阶段
sorted_students = reduce(lambda acc, item: acc + item[1], mapped_data, [])
print(sorted_students) FAQs
Q1: MapReduce框架是如何工作的?
A1: MapReduce框架主要由两个阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对,在Reduce阶段,所有具有相同键的值被组合在一起进行处理,这两个阶段之间还有一个Shuffle阶段,它会将所有具有相同键的键值对分组在一起,Reduce阶段的输出就是最终的处理结果。
Q2: MapReduce框架有哪些优点?
A2: MapReduce框架有以下优点:
高度可扩展性:可以轻松地在多台机器上运行,以处理大规模数据集。
容错性:如果某个任务失败,框架会自动重新分配任务到其他节点上执行。
简化编程模型:开发者只需要关注数据处理的逻辑,而不需要关心底层的分布式计算细节。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/978414.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复