


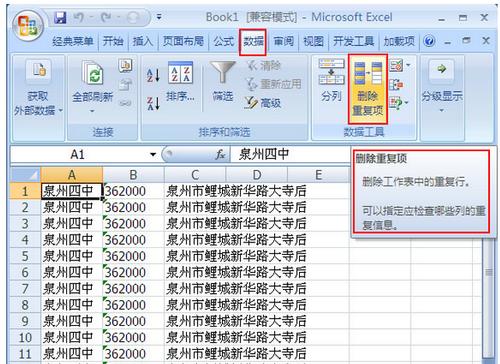
MySQL找出多张表的重复数据并删除
在MySQL中,要找出多张表中的重复数据并删除它们,通常需要使用`JOIN`语句来连接这些表,然后使用`GROUP BY`和`HAVING`子句来识别重复的数据,一旦找到重复的数据,可以使用`DELETE`语句来删除它们,以下是一个简单的示例:

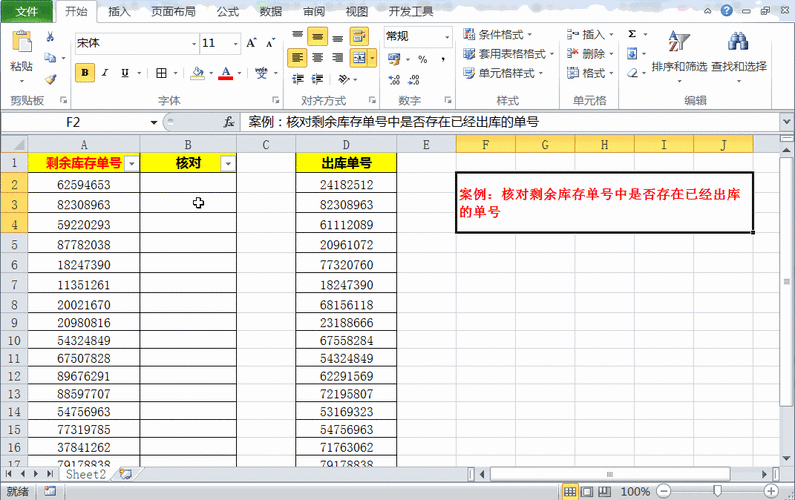
假设我们有两个表,`users`和`orders`,它们之间有一个关联字段`user_id`,我们希望找出那些在两个表中都存在的用户ID,并删除这些重复的用户。
“`sql
找出users表中重复的用户ID
SELECT user_id, COUNT(*) as count
FROM users
GROUP BY user_id
HAVING count > 1;
找出orders表中重复的用户ID
SELECT user_id, COUNT(*) as count
FROM orders
GROUP BY user_id
HAVING count > 1;
“`
上述查询将返回每个表中重复的用户ID及其出现的次数,我们可以使用以下语句来删除这些重复的用户:
“`sql
删除users表中重复的用户
DELETE u1 FROM users u1
INNER JOIN (
SELECT user_id, MIN(id) as min_id
FROM users
GROUP BY user_id
HAVING COUNT(*) > 1
) u2 ON u1.user_id = u2.user_id AND u1.id != u2.min_id;
删除orders表中重复的用户
DELETE o1 FROM orders o1
INNER JOIN (
SELECT user_id, MIN(id) as min_id
FROM orders
GROUP BY user_id
HAVING COUNT(*) > 1
) o2 ON o1.user_id = o2.user_id AND o1.id != o2.min_id;
“`
这里,我们首先通过子查询找出每个表中重复的用户ID及其最小的ID(即最早的记录),然后使用`DELETE`语句删除除最小ID之外的所有重复记录。
需要注意的是,执行删除操作前务必备份数据,以防意外发生,确保在执行任何删除操作之前仔细检查查询条件,以确保不会误删重要数据。
FAQs
问题1: 如何避免在删除过程中误删重要数据?
答案: 在进行任何删除操作之前,请务必备份您的数据库,您可以使用MySQL提供的备份工具如`mysqldump`或`mysqlhotcopy`来创建数据库的备份,在执行删除操作之前,可以先运行相同的查询以确认将要删除的记录是否正确。
问题2: 如果我想保留每个重复组中的一条记录,而不是全部删除怎么办?
答案: 如果您只想保留每个重复组中的一条记录,可以修改删除语句中的子查询部分,使其只选择每组中的最大ID或其他特定条件,如果您想保留最新的记录,可以使用`MAX(id)`代替`MIN(id)`,这样,您将保留每个重复组中具有最大ID的记录,而其他重复记录将被删除。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/978251.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复