

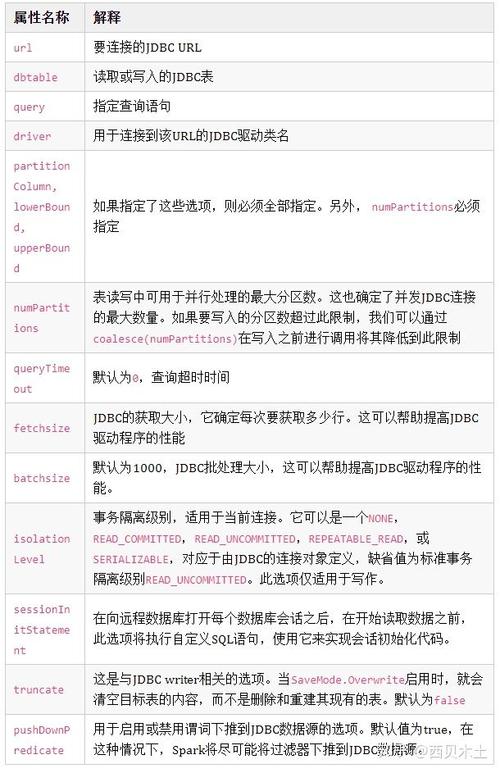
在数据库管理中,合并表是一种常见的操作,尤其当数据分散在多个表中时,对于MySQL数据库而言,有几种方法可以进行表的合并,处理大量小文件时,Spark小文件合并工具提供了有效的解决方案,下面将深入探讨这两种工具的使用和相关技术。
使用Navicat for MySQL合并数据库表:
1、打开Navicat for MySQL:启动Navicat for MySQL,这是一套功能强大的数据库管理与开发工具。
2、选择结构同步:在软件的菜单选项中,选择“工具”“结构同步”,这将允许用户比较和同步不同数据库中的表结构。
3、设置源和目标数据库:在结构同步界面,用户需要选择源数据库和目标数据库,这包括它们的连接和具体的数据库名称。
4、运行对比:点击“对比”,软件将分析两个数据库中的表结构差异,这一步骤是确保在合并过程中,数据的完整性不会被破坏。
5、执行查询修改:对比完成后,如果存在结构不一致,用户可以勾选所有需要修改的项,并点击“运行查询”以修正这些不一致性。
使用Spark小文件合并工具的方法如下:
1、配置环境:确保Hadoop和Spark已正确安装和配置,特别是coresite.xml、hdfssite.xml等配置文件,这些都需要在相应的资源目录下配置好。
2、编写Spark程序:利用Spark的API编写程序来读取小文件,并对其进行合并操作,可以使用repartition操作减少分区数量,从而减少生成的文件数。
3、执行合并操作:运行编写好的Spark程序,它将自动在HDFS上查找小文件,并将它们合并成较大的文件,这一过程大大提高了数据处理效率,特别是在进行大数据分析时。
4、监控和优化:持续监控合并操作的执行情况,根据实际效果调整Spark程序的配置和参数,以达到最优的合并效果。
效率与注意事项:
确保数据一致性:在进行任何形式的表合并前,检查表之间的关系及数据的一致性,避免数据冗余或丢失。
优化Spark配置:合理设置Spark的内存和CPU使用参数,可以显著提高小文件合并的效率。
安全性考虑:在操作数据库时,尤其是在生产环境中,确保采取适当的安全措施,如权限控制和数据备份。
测试与验证:在实施任何重大操作之前,应在测试环境中充分测试所有操作,确保它们按预期工作。
无论是使用Navicat for MySQL合并数据库表,还是使用Spark小文件合并工具处理小文件问题,关键在于理解各自的工作原理和最佳实践,通过正确的工具和方法,可以高效地解决数据管理中遇到的挑战。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/978127.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复