


DISTINCT关键字或者GROUP BY子句。如果要从students表中选取不重复的name,可以使用以下查询:,,“sql,SELECT DISTINCT name FROM students;,`,,或者使用GROUP BY:,,`sql,SELECT name FROM students GROUP BY name;,`,,这样可以得到没有重复的name`列表。在MySQL数据库中,数据去重是一个常见的维护任务,特别是在如题库系统等场景中,需要确保数据的规范性和准确性,本文将深入探讨如何在MySQL中去重复数据并保留唯一的条目,具体分析如下:

1、识别重复的数据
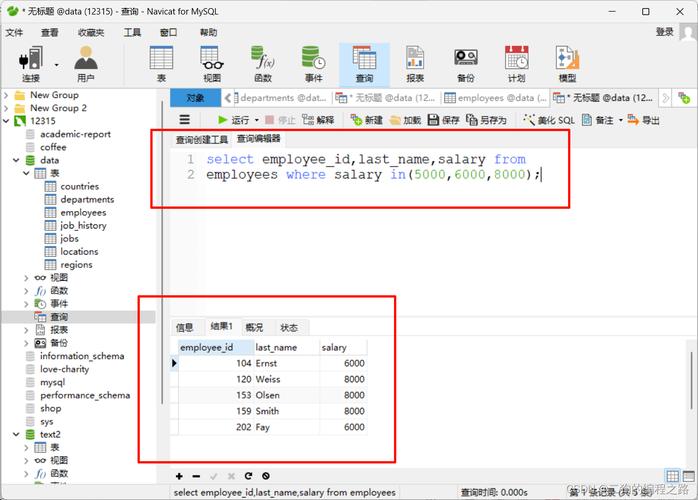
全表扫描:通过全表扫描,我们可以使用SQL语句来查询出重复的记录,如果在题库表中存在重复的试题,可以使用GROUP BY语句结合计数函数来找出哪些试题是重复的。
2、选择保留的数据
基于ID的选择:通常数据库中的主键(如s_id)可以用作识别唯一记录的依据,如果数据是自增长的,则选择具有最小ID值的记录作为留存数据是一种简便方法,这样做的好处是可以快速地通过索引进行筛选,提高效率。
复杂情况下的处理:当主键不是自增长ID而是UUID或其他类型时,情况会复杂一些,此时可以通过比较时间戳等其他字段来确定哪一条记录是最早添加的,从而选择这一条记录作为留存数据。
3、删除重复的数据
直接删除:找到需要保留的数据后,接下来的任务是删除其他重复的数据,在MySQL中,可以使用DELETE语句配合子查询来实现这一操作,重要的是在执行删除操作前,要确保已经做好了数据的备份,以防止误删除。
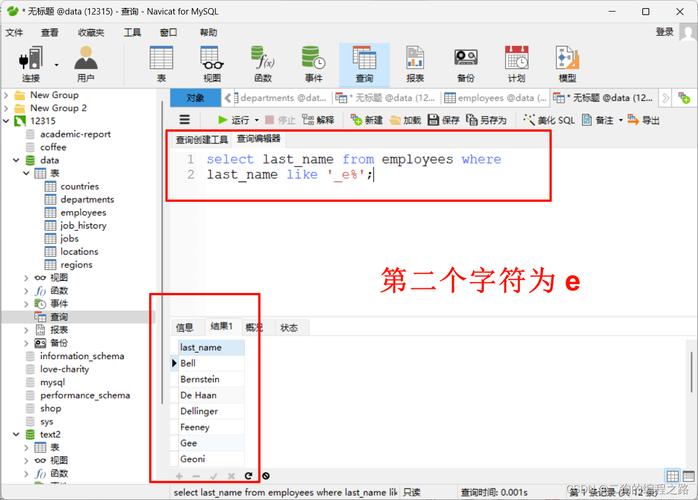
创建新表:另一种方法是创建一个新的表,只插入确定要保留的数据,然后再用新表替换掉旧表,这样做的好处是不会改变原表的结构,并且可以在新表中调整或优化结构。
4、验证去重效果
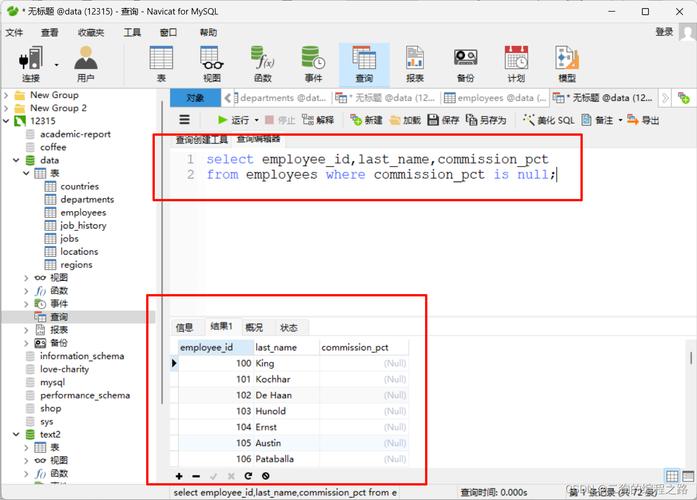
数据对比:完成去重操作后,应再次进行数据对比,确认重复数据已被正确删除,且每条应保留的数据都未受到影响。
功能测试:特别是在题库系统中,额外的功能测试能帮助确保去重后的数据集在实际应用中能正常工作,例如自动组卷、抽题等功能都需要测试是否因去重操作受到影响。
5、预防未来重复数据的产生
优化输入机制:为防止未来再有重复数据的输入,应优化数据的录入和校验流程,在添加新试题之前,程序应先检查该试题是否已存在于数据库中。
使用唯一约束:在数据库设计时,对于关键字段如题库系统中的题干、选项等,可以设置唯一约束,从数据库层面防止重复数据的插入。
在了解以上内容后,以下还有几点需要注意:
在进行去重操作前,一定要备份数据,以便在操作失误时能迅速恢复。
去重操作完成后,应监控数据库性能,因为大量的删除操作可能会对数据库性能产生短期影响。
考虑到数据的安全和完整性,去重操作应由有经验的数据库管理员或开发人员执行。
结合上述信息,去重不仅要在技术上谨慎处理,还要在流程和策略上进行优化,以确保数据的长期健康和系统的稳定运行,通过这些步骤和注意事项,您可以有效地在MySQL数据库中去除重复数据,同时保留有价值的信息。
相关问答FAQs
问:如何避免因去重操作导致的数据丢失?
答:在进行去重操作之前,应该做好数据备份工作,操作时应先在测试环境中进行尝试,确认无误后再在生产数据库中执行,确保删除的动作只针对确实需要移除的数据,并且要有回滚计划以应对可能的误操作。
问:如果数据量很大,有什么方法可以优化去重的效率?
答:对于大数据量的表进行去重,可以考虑以下优化措施:使用索引来加快查询速度;在非高峰时段执行去重操作减少对系统的影响;分批进行去重操作,避免一次性负载过大;以及考虑使用更高效的算法或工具来进行数据处理。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/976799.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复