


python,class Student:, def __init__(self, name, age, grade):, self.name = name, self.age = age, self.grade = grade,“,,在这个例子中,我们定义了一个名为Student的类,它有三个属性:name、age和grade。我们还定义了一个构造函数,用于初始化这些属性。在Hadoop MapReduce框架中,自定义对象的使用是提升数据处理灵活性和效率的关键,通过创建自定义对象,开发人员可以更精准地控制数据的输入输出格式,以及如何在Map和Reduce阶段处理数据,本文将深入探讨如何在MapReduce中创建和使用自定义对象,包括对象的序列化、排序规则的定制,以及使用自定义对象时的最佳实践。
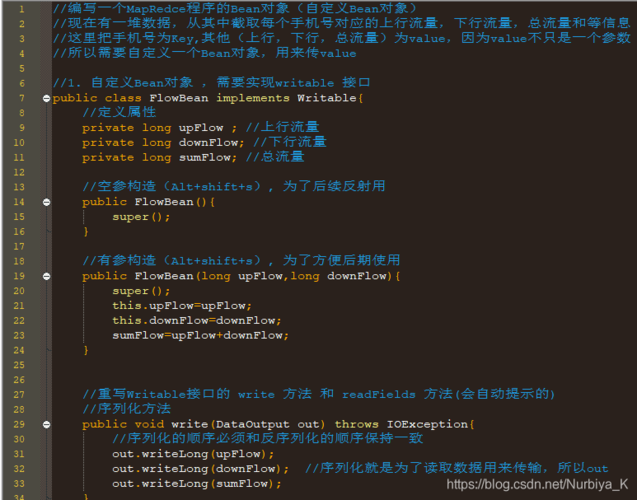

自定义对象的序列化
在MapReduce中,为了在各个阶段有效地传输和处理自定义对象,对象必须实现序列化,Hadoop提供了简洁快速的序列化机制,这比Java默认的序列化更为高效,要使自定义对象可序列化,最简单的方法是让你的类实现Writable接口,实现此接口需覆盖write(),readFields()方法:
write()方法用于将对象的属性写入到DataOutput流中。
readFields()方法则从DataInput流中读回属性值,以便在反序列化时重建对象。
如果有一个表示电话数据的PhoneData类,包含上行流量和下行流量,应如此实现序列化:
public class PhoneData implements Writable {
private long uploadTraffic;
private long downloadTraffic;
@Override
public void write(DataOutput out) throws IOException {
out.writeLong(uploadTraffic);
out.writeLong(downloadTraffic);
}
@Override
public void readFields(DataInput in) throws IOException {
uploadTraffic = in.readLong();
downloadTraffic = in.readLong();
}
} 这种方式确保了对象在MapReduce的不同阶段能够被正确地传输和重建。
自定义对象的排序
在MapReduce中,key的默认行为是按字典序升序排序的,如果需要按不同的规则排序,或者使用自定义对象作为key,则需要进行一些额外的操作,自定义对象需要实现Comparable接口,并重写compareTo()方法来定义排序规则,这对于确保Reduce阶段能正确归类和处理数据至关重要。
假设现在需要对PhoneData类实例按键值(某种唯一标识符)排序,可以这样做:
public class PhoneData implements Writable, Comparable<PhoneData> {
private String phoneID; // 假设phoneID是唯一标识符
// ...其他字段和方法...
@Override
public int compareTo(PhoneData other) {
return this.phoneID.compareTo(other.phoneID);
}
// 实现write和readFields方法...
} 通过这种方法,可以确保在MapReduce过程中,具有相同phoneID的PhoneData对象会被正确地分组并传递给同一个Reduce任务。
使用自定义对象的最佳实践
合理设计自定义对象
封装性:确保每个自定义对象都有明确的职责,避免过于复杂的对象设计,这会降低代码的可维护性和扩展性。
性能考量:考虑到序列化和反序列化的性能影响,应尽量减少对象的大小和复杂性,比如避免使用过大的数组或复杂的数据结构。
测试自定义对象的序列化和排序
单元测试:为自定义对象的序列化和排序实现编写单元测试,确保它们在各种情况下都能正常工作。
性能测试:评估大量数据的序列化和排序性能,确保它们不会成为性能瓶颈。
相关问答FAQs
Q1: 如何处理自定义对象中的复杂类型字段?
A1: 对于包含复杂类型(如列表、数组等)的字段,直接序列化可能较为复杂且容易出错,一种常见的做法是将复杂类型的数据拆分成几个基本类型的字段,分别进行序列化和反序列化,可以考虑将这些复杂数据存储在外部数据结构中(如HashMap),仅序列化其键值。
Q2: 自定义对象的并发处理安全性如何保证?
A2: 在Hadoop MapReduce中,自定义对象可能会被多个mapper或reducer并发访问,为确保线程安全,应避免在自定义对象中使用非线程安全的字段(如简单的数组)或方法,如果必须使用,可以通过加锁机制或其他同步策略来保证数据的一致性和完整性。
通过上述讨论,我们可以看到在Hadoop MapReduce中使用自定义对象不仅增加了编程的灵活性,也带来了一定的挑战,特别是在对象序列化和排序方面,理解并遵循最佳实践,可以帮助开发者有效利用这一功能,同时保证数据处理的准确性和效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/976347.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复