


FileSystem.get方法读取HDFS上的配置文件,然后解析并设置相应的配置项。在大数据技术中,MapReduce框架是处理大规模数据集的一种重要工具,作为由Google提出并广为人知的计算模型,MapReduce允许编程人员在不会分布式并行编程的情况下,轻松地将自己的程序运行在分布式系统上,完成海量数据的计算,在运行MapReduce作业时,合理地读取配置文件成为优化作业和确保其稳定性的关键步骤,本文旨在全面探讨MapReduce如何读取配置文件,并分析其中常见的操作方法及其适用场景。

我们可以将配置文件打包进MapReduce应用中,这种方式适用于配置信息较小,且不常变动的情况,应用中一些基础的配置参数,如内存大小限制、日志级别设定等,都可以在开发阶段被硬编码或通过小型配置文件的形式直接打包,这样做的好处在于简化了部署过程,减少了运行环境对外部资源的依赖。
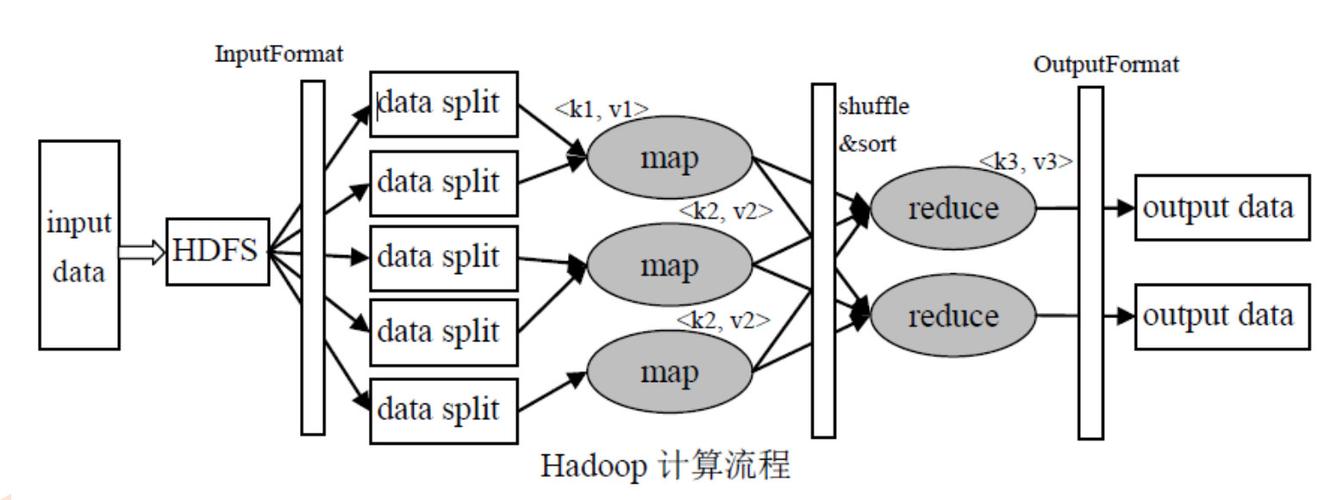
针对需要动态加载配置信息的场景,MapReduce提供了从HDFS(Hadoop Distributed File System)通过参数传递加载配置文件的方法,这种方法适合于大型的配置文件或者需要在不同作业之间共享相同配置的情况。coresite.xml和hdfssite.xml是Hadoop的核心配置文件,分别管理通用配置和HDFS配置,而mapredsite.xml则专门用于配置MapReduce任务,这些文件通常存放在HDFS上,通过在提交作业时指定相关参数,即可让作业在运行时加载相应的配置信息。
遍历HDFS目录的操作也是MapReduce读取配置文件的一种方式,在某些情况下,可能需要动态获取HDFS上多个配置文件的信息,这时可以通过编写特定的MapReduce作业来遍历HDFS目录,读取并解析配置文件,此操作不仅提高了处理配置文件的灵活性,也为处理多文件场景提供了可能。
深入分析MapReduce框架中的配置文件种类及其作用,在Hadoop环境中,主要的配置文件包括coresite.xml、hdfssite.xml和mapredsite.xml等。coresite.xml包含了Hadoop的最基本配置,如Hadoop的临时文件夹位置、Hadoop文件系统的URI等;hdfssite.xml则涉及到HDFS更具体的设置,比如副本数量、块大小等;而mapredsite.xml则专注于MapReduce作业的配置,如压缩映射输出、缩减任务数量的设置等,正确理解每个配置文件的作用,对于优化MapReduce作业至关重要。
归纳上述内容,MapReduce读取配置文件的方式主要有两种:一是将小型配置文件打包进应用,二是从HDFS中通过参数传递加载,除此之外,遍历HDFS目录也是一种灵活的操作方式,在实际操作中,根据配置文件的大小、变更频率以及作业对配置信息的动态需求,可以灵活选择最适合的读取方式。
综上,MapReduce读取配置文件是大数据处理中的一个基础环节,理解并掌握各种读取方法对于提高作业效率和稳定性具有重要意义。
相关问答FAQs
1. MapReduce是否可以在运行时动态更改配置?
答:是的,MapReduce可以在运行时通过参数传递或遍历HDFS目录的方式来动态加载或更改配置,这使得作业能够适应不同的运行环境和需求,提高了处理大规模数据集时的灵活性和效率。
2. 如何选择合适的MapReduce配置文件读取方式?
答:选择MapReduce配置文件读取方式时,需要考虑配置文件的大小、变更频率以及作业对配置信息的动态需求,小型且不常变动的配置可以打包进应用,而大型或需要动态加载的配置则适合存放在HDFS并通过参数传递加载,若需要处理多个配置文件,遍历HDFS目录也是一个可行的选项。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/976291.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复