


在当今信息时代,文本数据呈现出爆炸式的增长,为了高效地处理和分析这些数据,MapReduce框架被广泛使用,尤其是在文本分类任务中显示出了其强大的处理能力,文本分类是将文本资料根据其内容自动归入预定义的类别中的过程,常用于新闻分类、垃圾邮件检测、情感分析等场景,下面将深入探讨如何利用MapReduce进行文本分类,并附上相关代码示例及常见问题解答。
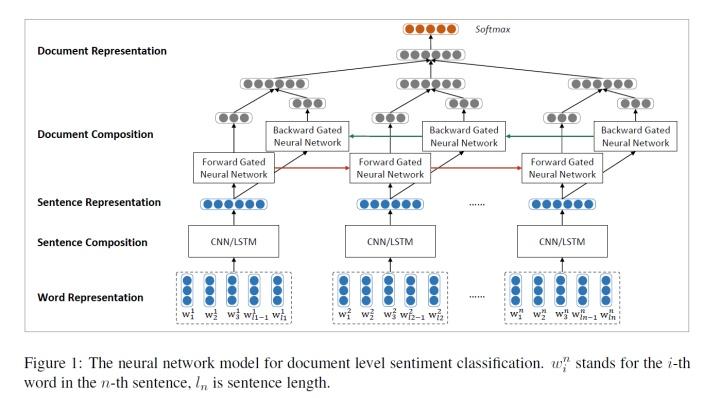
了解MapReduce的基本概念至关重要,MapReduce是一种编程模型,用于大规模数据集(大于1TB)的并行运算。"映射(Map)"阶段,系统将输入数据分成小块,分别发送给不同的处理节点;每个节点处理其分得的数据,并生成中间键值对。"归约(Reduce)"阶段,系统将所有中间值根据键进行聚合,得到最终结果,这种分布式计算方式极大地提高了数据处理的效率和速度。
我们具体看看如何在文本分类中应用MapReduce,假设我们有一个大型的文本数据集,需要将这些文本归类到预设的几个主题中,这一过程可以分为几个步骤:
1、文本预处理:包括去除停用词、标点符号、数字等,以及将文本转换为小写以统一格式。
2、文本分词:将文本拆分为单词或词汇单元,常用的中文分词工具有jieba、hanLP等。
3、构建文档词项矩阵:统计每个词项在各文档中出现的频率。
4、特征选择:通过TFIDF等方法选取有区分度的词项作为特征。
5、训练分类模型:使用朴素贝叶斯、支持向量机等算法训练分类器。
6、预测与评估:对新文档进行分类,并评估模型的准确性。
让我们通过一个简化的例子来展示MapReduce在文本分类中的应用,设有以下三个阶段的MapReduce作业:
Map阶段
输入:大量未分类的文本数据。
处理:每个Mapper节点接收一部分文本数据,执行文本预处理和分词操作,然后输出<key, value>对,其中key是文档ID,value是词项。
def map(document_id, document_content):
words = preprocess_and_segment(document_content)
for word in words:
emit(document_id, (word, 1)) Reduce阶段
输入:Mapper输出的<key, value>对。
处理:每个Reducer节点负责一组特定的key(即文档ID),对其对应的词项列表进行聚合,生成文档词项矩阵。
def reduce(document_id, values):
term_frequency = defaultdict(int)
for value in values:
term_frequency[value[0]] += value[1]
emit(document_id, term_frequency) 第二个MapReduce作业
输入:第一个Reduce阶段的输出。
处理:再次进行Map操作,将每个文档转换为特征向量,并进行局部权重计算(如TFIDF)。
def map(document_id, term_frequency):
feature_vector = compute_feature_vector(term_frequency)
emit(document_id, feature_vector) 之后,这些特征向量可以用于训练一个分类器,例如朴素贝叶斯分类器,我们可以使用这个训练好的模型来预测新文档的类别。
通过上述讨论,可以看出,使用MapReduce进行文本分类涉及多个步骤和技术细节,我们将补充一些在实际操作中可能会用到的技巧和注意事项:
优化存储格式和数据传输可以显著提高MapReduce作业的性能。
合理设置MapReduce作业中的Map和Reduce函数的数量,平衡负载,避免单个节点过载。
迭代算法(如某些机器学习算法)可能需要多次MapReduce循环,应尽量减少循环次数以提高计算效率。
在结束本文之前,我们来解答一些关于使用MapReduce进行文本分类时常见的问题:
FAQs
Q1: 如何处理多语言混合的文本数据?
A1: 对于多语言混合的文本数据,可以使用支持多种语言的分词工具,如stanford nlp,确保不同语言的文本都能得到正确处理,在特征选择时考虑语言特性,选择适合各自语言的特征提取方法。
Q2: MapReduce在处理大规模文本数据时遇到性能瓶颈怎么办?
A2: 遇到性能瓶颈时,可以考虑以下几个方面进行优化:增加更多的计算资源(如增加节点数量)、优化数据存储格式(如使用序列化数据格式)、调整Map和Reduce函数的复杂度、以及使用更高效的数据交换和传输机制。
通过MapReduce进行文本分类不仅可行而且高效,特别是在处理大规模数据集时,通过以上详细的步骤介绍和技巧分享,相信读者能够对如何使用MapReduce进行文本分类有了更深入的理解和掌握。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/975469.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。




发表回复