


在MapReduce框架中,合理设置Map任务的数量是至关重要的,因为它直接影响作业的执行时间和资源利用率,下面将详细探讨如何配置Map任务数量,以优化MapReduce作业的性能,具体分析如下:
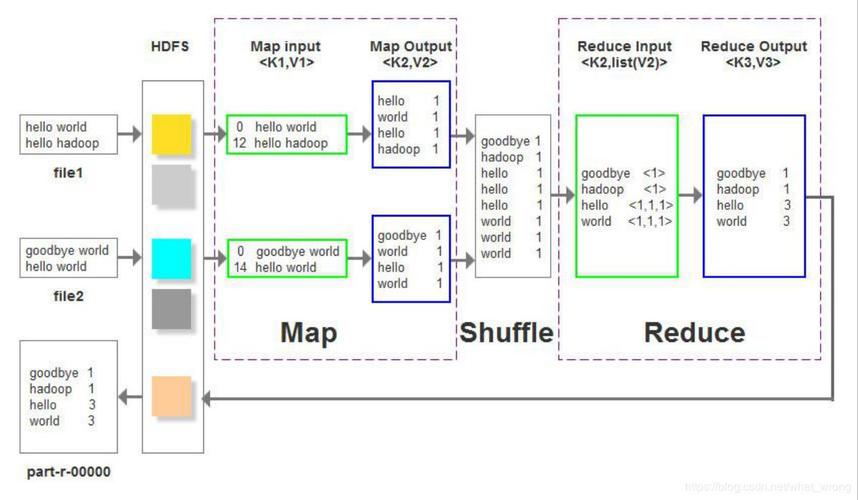

1、MapReduce作业流程
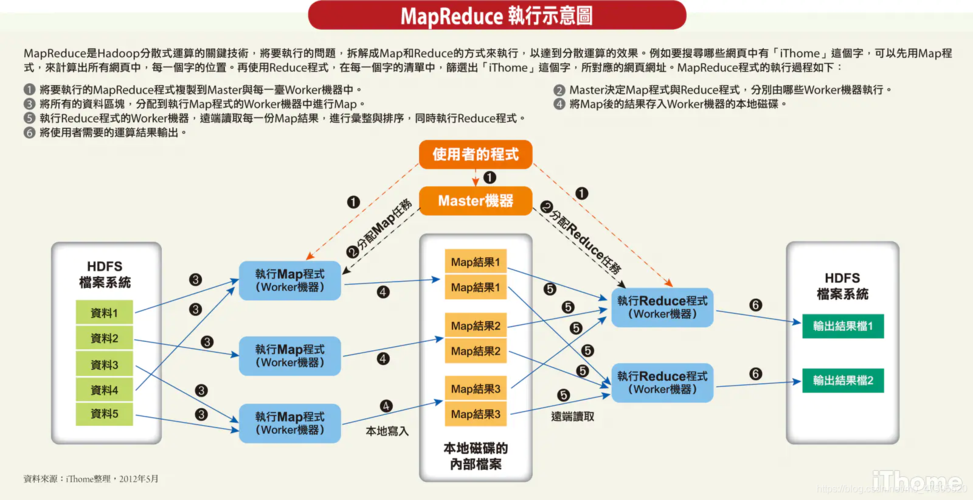
作业提交与资源申请:用户提交MapReduce作业后,ApplicationMaster负责申请所需计算资源,这一阶段包括资源的分配和任务的初始化。
Map阶段的角色:Map阶段的主要任务是将输入数据拆分成小块,由各个Map任务并行处理,每个Map任务处理一个数据块并生成中间结果。
Reduce阶段的角色:Reduce阶段的任务是从Map任务接收数据,进行整合操作,最终输出所需的结果。
并行度的重要性:通过调整并行度和分区数,可以优化数据处理速度和提高资源利用率。
2、Map任务数量的决定因素
数据规模:输入数据的大小是决定Map任务数量的重要因素之一,较大的数据集通常需要更多的Map任务以实现并行处理。
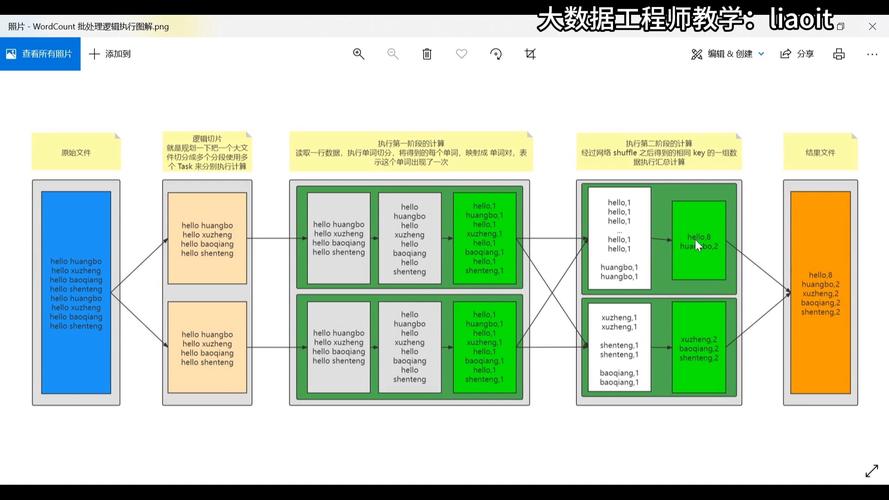
集群资源情况:集群中可用的资源量,如CPU核心数和内存大小,也会影响Map任务的理想数量。
节点配置:每个节点的配置,包括CPU核心数量和能同时计算的slot数量,也是必须考虑的因素。
3、Map任务数量的具体设置
公式应用:一种常见的做法是将Reduce任务的数量设置为0.95或0.75乘以(节点数*每个节点的最大Reduce任务数)。
与CPU核心的关系:Map任务的数量通常与CPU的核心数量有关,理想的配置是让每个CPU核心执行一个Map任务。
性能调优:根据实际作业的执行效率和资源使用情况,适当调整Map任务的数量,以达到最佳性能。
4、系统配置参数
JVM堆内存大小设置:通过mapreduce.map.java.opts和mapreduce.reduce.java.opts为Map和Reduce任务设置合适的JVM堆内存大小,确保任务高效运行而不出现内存溢出。
作业优先级设置:通过调整mapreduce.job.priority参数,可以设置作业的优先级,这在某些情况下有助于更公平地分配资源。
5、环境兼容性考量
Hadoop版本的影响:不同版本的Hadoop可能在配置参数和推荐设置上有所不同,在Hadoop 3.x中,这些参数和设置方式可能与早期版本略有差异。
平台兼容性:除了Hadoop外,其他大数据处理框架如Spark也有类似的设置,但具体参数和配置方法需要根据具体平台进行调整。
在优化MapReduce作业时,合理设置Map任务的数量是一个关键步骤,通过考虑数据规模、集群资源情况、节点配置以及系统参数等多个因素,可以有效地提高作业的处理速度和资源利用率,考虑到不同环境和平台可能有特定的配置要求,应根据具体情况调整设置,以实现最佳的性能表现。
FAQs
Q1: Map任务数量是否越多越好?
A1: 并非如此,虽然增加Map任务的数量可以提高并行处理能力,但过多的任务可能会导致管理开销增大,影响整体性能,合理的数量应该基于数据规模和资源情况来设定。
Q2: 如何确定最合适的Map任务数量?
A2: 可以通过试验和监控实际运行情况来确定,开始时可以参考“节点数*每个节点的最大Map任务数”的0.75到0.95倍作为一个初始设置,然后根据作业的实际表现进行调整。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/975233.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复