


MapReduce概念与使用方式


MapReduce是一个高效的分布式运算编程框架,它通过将大规模数据处理任务分拆成多个小任务,并行处理,以实现对海量数据的快速处理,MapReduce模型主要包括两个阶段:Map阶段和Reduce阶段,将深入探讨如何使用MapReduce,从编程模式、实际应用案例以及操作步骤等多个角度进行分析。
MapReduce的基本概念和工作原理
1、MapReduce的核心思想
MapReduce的核心思想是将复杂的任务分解为多个简单的子任务,这些子任务独立运行在不同的数据片段上,这种模型非常适合于海量数据集的处理,因为它能够利用集群的计算能力,并行处理数据。
2、Map和Reduce阶段的作用
在Map阶段,框架将输入数据分成小块,然后分别传给Mapper函数,Mapper函数处理这些小块数据,生成键值对形式的中间结果,而在Reduce阶段,框架根据键值对的键进行排序和分组,传递给Reducer函数,由Reducer完成最终的结果输出。
3、Hadoop MapReduce的设计构思
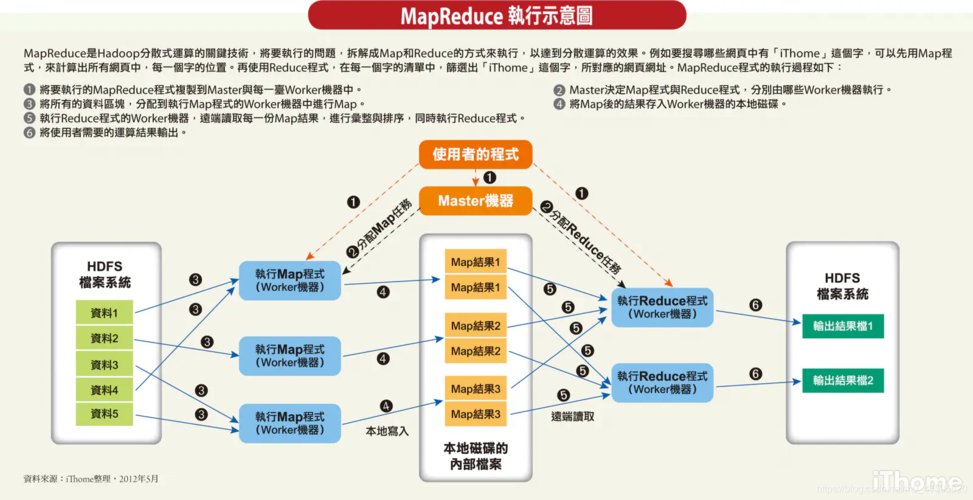
Hadoop MapReduce设计允许开发人员专注于数据的业务逻辑处理,而不需要关心底层的分布式计算细节,这使得编写处理海量数据的程序变得简单高效。
经典例子——WordCount的实现
1、Word Count程序任务
Word Count是MapReduce的经典示例,用于统计文本文件中各单词的出现次数,这个案例清晰地展示了MapReduce如何处理实际问题。
2、单机模式下的测试方法
可以在非HDFS环境下,使用Hadoop框架来模拟Word Count程序的运行,这通常通过启动一个Hadoop镜像的容器来实现。
3、详细操作步骤
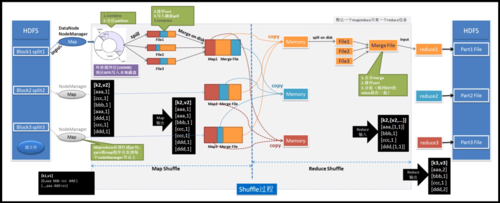
操作步骤包括准备输入文件、编写Mapper和Reducer类,配置作业,并提交到Hadoop执行,执行后,可以查看输出的结果文件以验证程序的正确性。
编程实践和注意事项
1、MapReduce编程接口
MapReduce提供了Mapper和Reducer类的编程接口,开发者需要继承这些类,并实现具体的映射和归约逻辑。
2、设计模式和最佳实践
在MapReduce编程中,有一些设计模式和最佳实践需要遵循,比如合理设计键值对以优化数据的传输和排序,以及注意内存管理等。
3、序列化机制和类型支持
Hadoop中的序列化机制是核心,它影响到数据的传输和存储,了解Hadoop支持的数据类型对于开发高效的MapReduce应用同样重要。
FAQs
Q1: 如何确保MapReduce程序的效率?
A1: 确保MapReduce程序效率的关键因素包括合理划分Mapper和Reducer的任务以保证负载均衡,避免数据传输时的瓶颈,以及优化I/O操作和内存使用。
Q2: 在编写MapReduce程序时有哪些常见的错误?
A2: 常见的错误包括不合理的数据类型选择导致内存溢出、忽视数据倾斜问题导致某些节点负载过重,以及缺乏对程序异常处理的考虑,影响程序的健壮性。
MapReduce作为一个强大的分布式计算框架,为处理大规模数据集提供了可能,通过合理的编程和实践,可以充分发挥其优势,解决复杂数据处理问题。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/971073.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复