


在当前的大数据时代,数据去重是一项常见而重要的操作,尤其在处理大规模数据集时,Hadoop MapReduce提供了一个强大的框架来处理此类问题,下面将深入探讨如何使用Hadoop MapReduce进行数据去重,包括其原理、实施步骤、代码实例和结果验证。
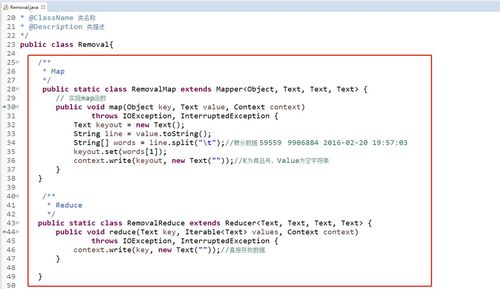

1、数据去重的原理
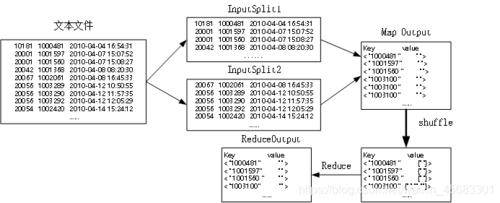
基本概念:数据去重是一个筛选过程,旨在移除数据集中的重复数据项,以保留唯一项或减少数据冗余,在MapReduce中,这一过程通常涉及两个主要阶段:Map阶段和Reduce阶段。
Map阶段:在此阶段,系统会读取原始数据并将其分为多个小数据块,每个数据块将被送入不同的Mapper函数,该函数负责处理这些数据块并生成一系列键值对。
Reduce阶段:Reducer的工作是接收来自Mapper的所有输出,并基于键(key)将所有的值(value)聚合起来,在数据去重的场景中,Reduce阶段主要是去除具有相同键的重复项。
2、案例需求与实施步骤
案例背景:设想一个场景,需要对两个含有重复数据的文件进行去重,这不仅能帮助理解数据去重的实际应用,还能体现其在处理大规模数据集上的能力。
具体实施:首先启动必要的Hadoop服务,然后创建和上传待处理的数据文件,通过自定义Mapper和Reducer类实现具体的数据处理逻辑,最后通过Driver程序运行去重作业,并查看结果以验证去重效果。
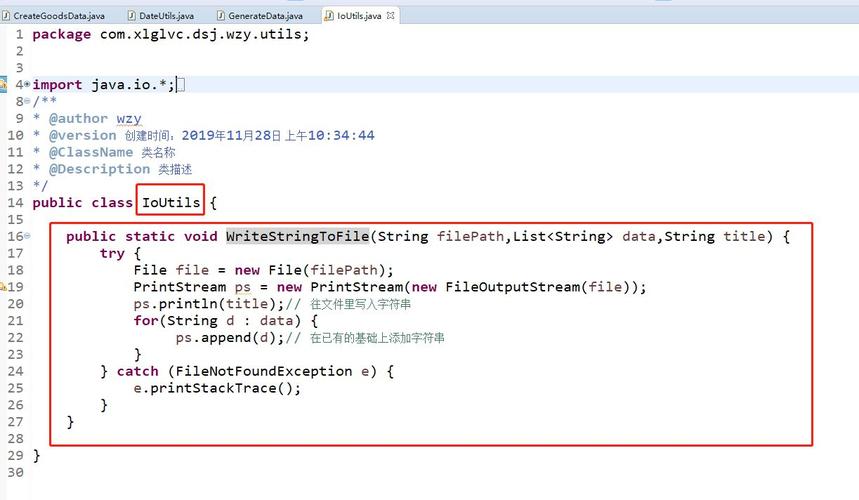
3、MapReduce数据去重的代码实现
Mapper类的实现:在Mapper类中,可以通过读取每一行数据,并将每行数据转换为键值对的形式,其中键为数据项,值为恒定的单一标记。
Reducer类的实现:Reducer的任务相对简单,只需忽略重复的键,仅保留每个键对应的第一个值即可实现去重。
驱动程序:主类驱动程序负责配置和提交MapReduce作业,监控作业的执行,并确保输入输出路径设置正确。
4、数据去重的运行结果与验证
查看结果:作业完成后,应检查输出目录,确认去重后的数据文件已正确生成。
结果验证:可以通过比较去重前后的数据量或使用数据校验工具来验证去重的正确性和完整性。
5、优化与进阶
性能优化:在处理极大规模的数据集时,可以考虑优化Mapper和Reducer的代码,例如使用更高效的数据结构或算法。
高级应用:除了基本的去重功能外,还可以结合其他数据处理操作,如数据清洗和格式转换,进一步增加数据处理的效率和质量。
通过上述深入分析,可以更好地理解使用MapReduce进行数据去重的全过程,以下是一些相关问答,以解决可能的具体疑问。
FAQs
如何提高MapReduce数据去重的效率?
优化数据读写:优化数据的读写方式,如使用序列化技术减少数据传输量。
调整内存配置:根据具体任务的需求调整Mapper和Reducer的内存配置,以提升处理速度。
如何处理去重后的数据不一致问题?
数据核查:定期进行数据完整性和一致性核查。
日志分析:利用系统日志分析处理过程中可能出现的问题,及时修正程序错误。
通过以上详细讨论,相信你已经对使用Hadoop MapReduce进行数据去重有了全面而深入的理解。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/970985.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复