


在探讨Hadoop框架中的MapReduce与其他组件的关系时,首先需要明确的是,MapReduce是一个计算模型,专门用于处理和生成大规模数据集,该模型主要包括两个部分:Map和Reduce,分别对应数据的分拆和聚合过程,实现高效的数据处理,具体到Hadoop框架中,MapReduce的运行依赖于多个关键组件的配合,这些组件包括JobTracker和TaskTrackers等,它们共同确保了数据处理任务的高效执行。
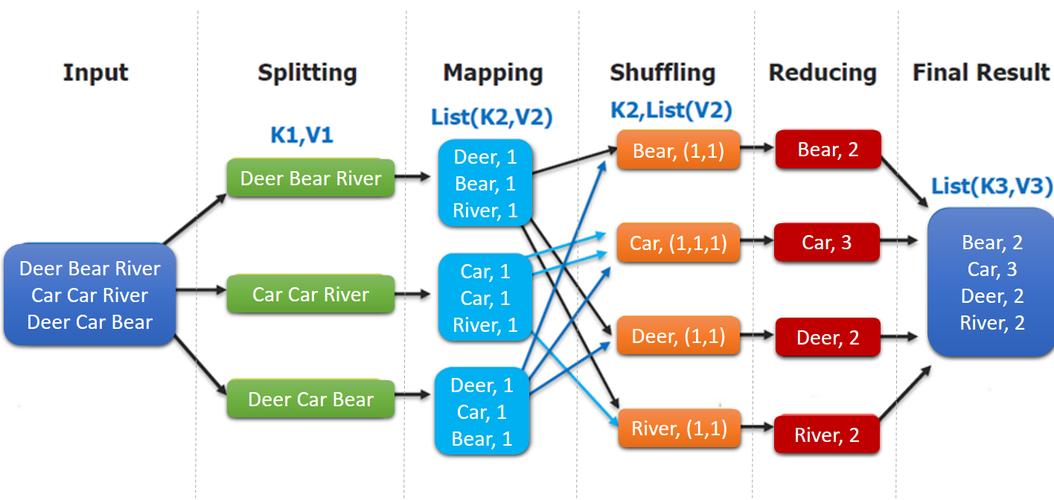

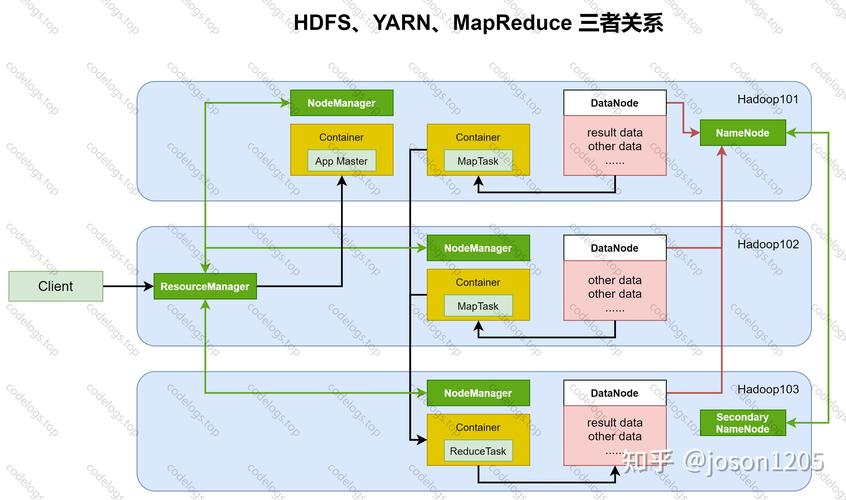
MapReduce作业的生命周期开始于客户端,通过JobClient类将应用和相关配置参数打包存储到HDFS,这一步骤是作业提交的基础,确保了所有必要信息的集中管理和分发,一旦作业被提交,JobTracker—作为MapReduce框架中的核心组件—扮演着主控角色,它负责协调和管理整个作业的执行过程,包括任务的分配、监控、以及失败任务的重新执行指导。
在Hadoop的主/从架构中,JobTracker位于主节点,而从节点则部署有TaskTrackers,每个TaskTracker负责在其所在节点上执行任务,同时与JobTracker保持通信,报告任务进度和状态,这种结构使得MapReduce可以在多节点上并行处理数据,极大提高了数据处理的效率和速度。
具体到MapReduce的执行,它分为Map阶段和Reduce阶段,由对应的MapTask和ReduceTask实现,MapTask处理输入数据,生成中间结果;ReduceTask则负责整合这些中间数据,输出最终结果,这两个任务类型均由TaskTracker启动和管理,确保了数据处理的顺利进行。
除了上述核心组件外,Hadoop的分布式文件系统(HDFS)也在MapReduce作业执行中发挥着重要作用,HDFS负责在各个节点上存储数据,并实现了高吞吐率的数据读写能力,这为MapReduce提供了可靠的底层数据存储和访问解决方案,使得大规模数据集的处理成为可能。
可以看出MapReduce在Hadoop生态系统中的执行不仅依赖其本身的设计,如Map和Reduce任务的划分,还密切依赖于其他Hadoop组件的支持,包括JobTracker和TaskTrackers的任务调度与管理,以及HDFS提供的数据存储服务,每一部分都在确保MapReduce能够高效、可靠地处理大规模数据中发挥着不可或缺的作用。
FAQs
1. MapReduce在数据处理中的主要挑战是什么?
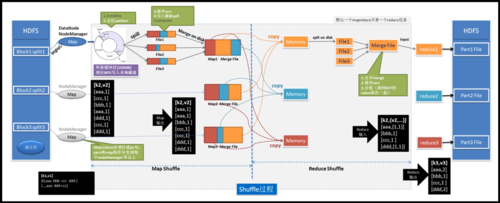
MapReduce虽然在处理大规模数据集方面非常有效,但它面临的主要挑战包括处理效率问题和系统的可扩展性,由于其严格的数据处理模式(先Map后Reduce),对于需要频繁迭代的算法或实时数据处理需求,MapReduce可能不是最佳选择,JobTracker的单点故障问题在早期版本的Hadoop中也是一大挑战,这直接影响了系统的容错性和稳定性。
2. 如何优化MapReduce作业的执行?
优化MapReduce作业执行的方法有多种,包括但不限于:合理设置Map和Reduce任务的数量,以确保负载均衡;使用压缩技术来减少数据传输量;优化数据存储格式以加快读写速度;以及合理配置内存和CPU资源,针对特定作业调整合并(combining)和分区(partitioning)策略也可以显著提高性能。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/968829.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复