


在云数据库环境中,确保数据的安全性和可用性是至关重要的,跨区域备份策略是一种有效的容灾手段,它通过将数据备份至不同的地理区域,来避免单点故障导致的业务中断或数据丢失,本文将详细解析如何为MSSQL云数据库设置跨区域备份策略,并提供一些实用性的例子和相关FAQs,帮助用户更好地理解和应用这一策略。


跨区域备份的重要性
跨区域备份的主要目的是为了提高数据的可靠性和系统的灾难恢复能力,当一个区域的数据中心因自然灾害、设备故障或其他不可预见的事件导致服务中断时,另一个区域的备份数据可以迅速恢复服务,从而最大限度地减少业务中断时间,这种备份策略也符合多地数据合规性要求,有助于企业满足法律法规对数据存储地点的规定。
设置跨区域备份策略的步骤
1、选择备份区域:首先确定哪个区域作为备份数据的存储地,理想的备份区域应与主数据库地理位置足够远,以减少共同受到灾害影响的可能性。
2、配置备份策略:通过云服务提供商的管理控制台或API调用设置备份策略,ModifyCrossBackupStrategy接口可以用来开启或关闭地域备份策略。
3、定期审核和测试:定期检查备份策略的配置是否正确,测试备份文件是否能在需要时成功恢复数据库,这包括检查备份文件的完整性和恢复过程的操作流程。
4、监控和维护:持续监控备份操作的状态,确认备份任务按计划执行,并处理任何失败的备份作业,维护日志记录和备份历史,以便审计和回溯。
实用性例子
假设一家电商平台使用云数据库RDS管理其客户数据,为了确保在地震等自然灾害中的业务连续性,他们决定启用跨区域备份,通过RDS管理控制台,该平台选择了一个远离主数据中心的区域作为备份区域,并设置了自动备份策略,几个月后,当他们的主数据库中心因维护需要临时关闭时,能够利用备份数据迅速恢复服务,几乎没有影响到用户体验。
相关FAQs
Q1: 修改跨区域备份策略有哪些限制?
A1: 如果实例已开启跨区域备份策略,调用接口进行修改时,只有保留天数的设置会生效,其他参数更改将被忽略。
Q2: 跨区域备份是否会影响数据库性能?
A2: 通常情况下,跨区域备份对主数据库的性能影响不大,因为大多数云服务提供商会在后台异步处理备份任务,确保不影响前台业务的响应速度。
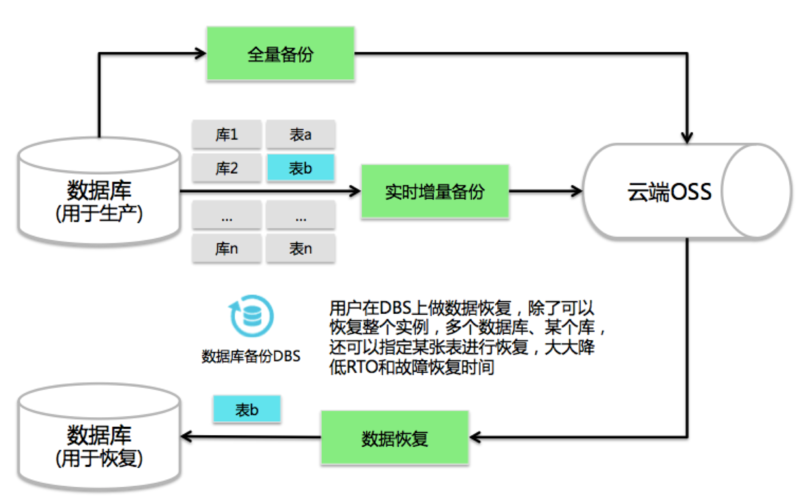
设置MSSQL云数据库的跨区域备份策略是一个复杂但极其重要的任务,通过合理选择备份区域、配置备份策略、定期审核及测试以及持续的监控和维护,可以显著提高数据的安全性和系统的整体可靠性,了解相关的接口约束和备份对性能的影响也是确保备份策略有效实施的关键因素。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/964098.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复