


MapReduce与MPI平台


MapReduce是一种编程模型,用于处理和生成大数据集,它的主要思想是将任务分解成两个阶段:Map阶段和Reduce阶段,在Map阶段,输入数据被分成多个小数据块,每个数据块由一个Map任务处理,生成一组中间键值对,这些中间键值对根据键进行排序和分组,以便将具有相同键的所有值聚集在一起,在Reduce阶段,每个Reduce任务接收一个键及其对应的一组值,并处理它们以生成最终结果。
MPI(Message Passing Interface)是一个标准库,用于在并行计算机上编写消息传递程序,它提供了一组函数,用于发送和接收消息,以及同步和协调并行任务的执行,MPI可以用于实现各种并行计算模型,包括MapReduce。
MapReduce在MPI平台上的实现
在MPI平台上实现MapReduce需要以下几个步骤:
1、初始化MPI环境:使用MPI_Init()函数初始化MPI环境,并获取当前进程的排名和总进程数。
2、分割输入数据:根据进程数将输入数据分割成多个数据块,每个进程负责处理一个数据块。
3、Map阶段:每个进程执行Map函数,处理其分配的数据块,并生成中间键值对。
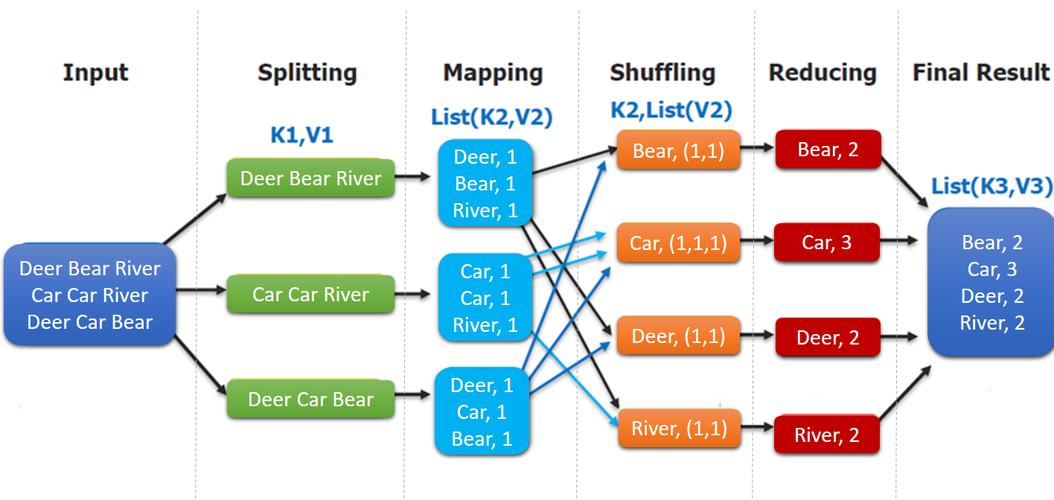
4、数据交换:使用MPI_Send()和MPI_Recv()函数将中间键值对发送到相应的Reduce进程。
5、Reduce阶段:每个Reduce进程接收到一个键及其对应的一组值,执行Reduce函数,并生成最终结果。
6、结果收集:将每个Reduce进程的结果收集到主进程中,以便进一步处理或输出。
7、MPI环境清理:使用MPI_Finalize()函数清理MPI环境。
优势与挑战
在MPI平台上实现MapReduce有以下优势:
高性能:MPI提供了低级别的通信原语,可以实现高效的数据传输。
灵活性:MPI允许程序员直接控制并行任务的执行和通信,可以根据具体需求优化性能。
可扩展性:MPI支持多种并行计算机架构,包括共享内存和分布式内存系统。
也存在一些挑战:
编程复杂性:MPI提供了低级的通信原语,需要程序员处理许多并行计算的细节,如数据分布、负载平衡和故障恢复。
调试困难:由于并行程序的复杂性,调试和测试MPI程序可能非常困难。
缺乏高级抽象:与一些更高级的并行计算框架相比,如Apache Hadoop或Apache Spark,MPI缺乏高级抽象和自动优化功能。
相关问答FAQs
Q1: 如何在MPI平台上实现MapReduce的容错机制?
A1: 在MPI平台上实现MapReduce的容错机制可以通过以下方法:
检查点和恢复:定期保存程序的状态,并在发生故障时从最近的检查点恢复。
任务复制:复制Map或Reduce任务,并将它们分配给不同的进程或节点,如果一个任务失败,可以使用其他副本的结果。
数据备份:将输入数据和中间结果存储在可靠存储中,以便在发生故障时重新计算。
Q2: 如何优化MPI平台上的MapReduce性能?
A2: 优化MPI平台上的MapReduce性能可以通过以下方法:
数据本地化:尽量将数据分配给本地磁盘上的进程,以减少数据传输开销。
负载平衡:根据每个进程的计算能力和网络带宽动态调整任务分配。
通信优化:使用集体通信操作(如广播、散播和归约)来减少通信开销。
I/O优化:使用异步I/O操作和非阻塞通信来提高数据传输效率。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/963128.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复