


if指令和return指令来实现。找到需要过滤爬虫的服务器块(server block),然后在其中添加以下代码:,,“,if ($http_user_agent ~* "爬虫的UserAgent特征") {, return 403;,},`,,将“爬虫的UserAgent特征”替换为实际的爬虫UserAgent特征,"Googlebot"。这样,当Nginx检测到符合特征的UserAgent时,会返回403禁止访问。在当今互联网时代,爬虫程序的广泛应用使得网站数据安全和服务器负载面临挑战,为了保护网站内容不被非法抓取,同时保证正常用户的访问体验,通过配置Nginx来过滤具有特定UserAgent特征的请求变得尤为重要,小编将详细介绍如何在Nginx中配置过滤爬虫的UserAgent。

1、了解UserAgent
基本概念:每当用户的浏览器向服务器发送请求时,请求头中会包含一个UserAgent字段,该字段描述了用户代理的信息,如浏览器类型、操作系统等。
重要性:对于服务器来说,分析这个字段是识别请求来源是常规浏览器还是爬虫程序的关键步骤。
2、Nginx中配置UserAgent过滤
检查请求:利用Nginx配置文件中的$http_user_agent变量,可以对请求的UserAgent进行检查。
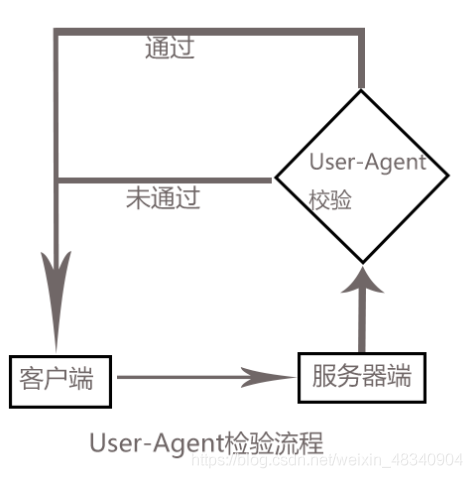
设置条件:如果UserAgent字段符合特定的模式或值,可以定义Nginx进行相应的处理,例如拒绝请求或返回错误页面。
3、配置实践
示例配置:下面的配置代码演示了如何对特定的UserAgent进行识别并拒绝访问。
“`nginx
location / {
if ($http_user_agent ~* "googlebot|bingbot|slurp") {
return 403;
}
}
“`
参数解释:上述配置中,~ 是一个大小写不敏感的正则表达式匹配,googlebot、bingbot和slurp分别代表谷歌、必应和雅虎的爬虫,当请求的UserAgent包含这些关键字时,服务器将返回403错误。
4、注意事项
白名单设置:合理设置白名单,避免误伤合法的搜索引擎爬虫,一些常见的爬虫UserAgent如下表所示:
| 搜索引擎 | UserAgent 部分关键字 | |
| googlebot | ||
| Bing | bingbot | |
| Yandex | yandexbot | |
| Baidu | baiduspider | |
| Sogou | sogou | |
| Seznam | seznambot |
黑名单与动态屏蔽:除了设置白名单外,还可以维护一个黑名单,定期更新以屏蔽新发现的恶意爬虫。
5、高级策略
自定义中间件:对于使用Scrapy等框架的开发者,可以通过修改请求头中的UserAgent字段为自定义值,从而绕过简单的UserAgent检查。
日志与监控:配置Nginx日志记录被阻止的请求,有助于分析爬虫行为,持续优化防护策略。
通过配置Nginx来过滤特定UserAgent的方法虽然简单有效,但也要警惕高级爬虫可能会伪造UserAgent,管理员需要持续关注爬虫行为的变化,并不断调整防护策略,确保不会对正常的搜索引擎爬虫造成影响,平衡好网站内容保护与用户体验之间的关系。
相关问题与解答
Q1: 是否可以阻止所有的爬虫?
A1: 不可以,虽然可以通过UserAgent过滤掉大部分普通爬虫,但高级爬虫可能会伪造UserAgent或采取其他手段绕过检测,完全阻止所有爬虫几乎是不可能的。
Q2: 过滤爬虫会不会影响SEO效果?
A2: 如果正确配置,只过滤掉恶意爬虫而不影响正常的搜索引擎爬虫(如Googlebot),那么对SEO不会产生负面影响,合理的爬虫管理策略应该能够区分正常爬虫与恶意抓取行为。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/954038.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复