


在大数据时代,数据仓库和数据分析任务常常涉及到大量数据的处理,Hive作为一个建立在Hadoop之上的数据仓库基础架构,通过将SQL查询转换为MapReduce任务处理大规模数据集,在实际应用中,经常会遇到需要连接(Join)两张大表的情况,如果执行效率低下,会严重影响数据处理的速度,优化Hive中的Join操作是提高整体查询性能的关键步骤,下面将详细探讨如何优化Hive中的Join操作:
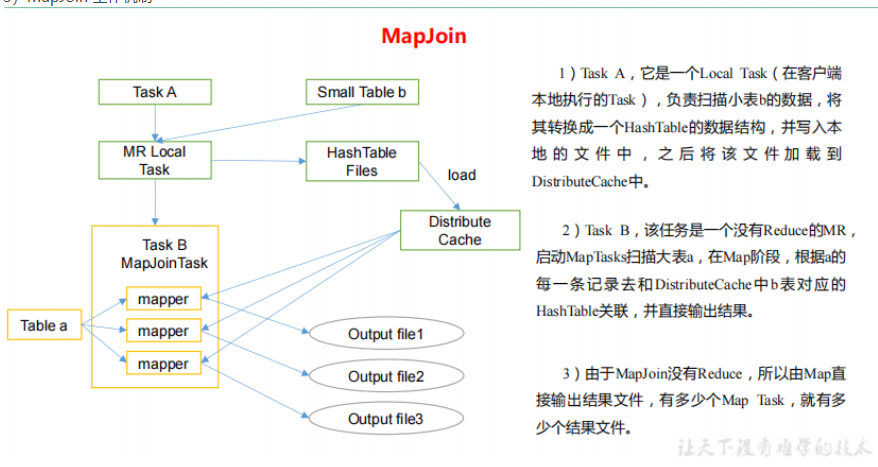

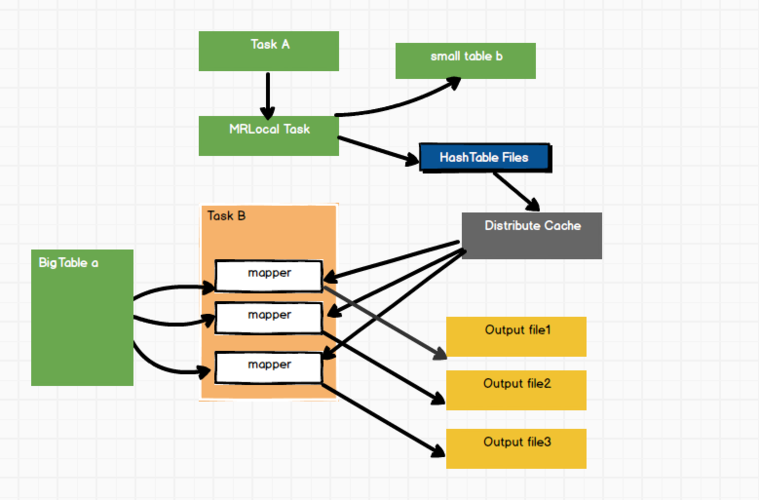
1、使用Map Join优化小表和大表的连接
Map Join原理:当一张小表与一张大表进行JOIN操作时,Map Join是一种高效的优化方式,该技术通过将小表加载到每个Map任务的内存中,这样在Map阶段即可直接执行JOIN操作,由于避免了Reduce阶段的文件连接,可以显著减少查询时间,尤其在处理数据倾斜时,能避免单个Reduce任务处理过多数据导致的性能瓶颈。
合理设置参数:为了启用Map Join,需要将小表放在JOIN操作的左边,同时可以通过调整一些参数来优化其性能,适当增加mapreduce.map.memory.mb(用于控制每个Map任务可用的内存)以确保小表能够完全载入内存中。
2、合理设计表的存储格式和分区
存储格式选择:在Hive中,选择合适的文件格式对查询性能有很大影响,使用ORC(Optimized Row Columnar)格式,它提供了良好的压缩率和快速的列访问,能显著提升查询速度。
表分区策略:合理地对表进行分区也可以提高JOIN操作的效率,通过在频繁用于JOIN的条件字段上进行分区,可以减少查询时需要处理的数据量。
3、采用合适的Join算法
SortMerge Join:当两个表都较大并且无法使用Map Join时,可以使用SortMerge Join,这种算法要求参与JOIN的表在JOIN键上预先排序,从而减少不必要的数据传输。
Hash Join:对于等值JOIN,Hash Join是一个有效的选择,它通过构建哈希表来加快数据连接的速度,但需要注意的是,Hash Join通常需要较多的内存资源。
4、优化数据倾斜问题
倾斜原因分析:数据倾斜是指部分Reduce任务处理的数据远多于其他任务,通常是由于JOIN操作中的KEY分布不均,识别并分析造成数据倾斜的原因,是解决此问题的第一步。
负载均衡策略:可采用Range分区或者在JOIN操作前进行数据采样,分析KEY的分布,然后根据分布情况进行分区或者增加Reducer的数量,以实现负载均衡。
5、合理配置硬件资源和调整并行度
硬件资源配置:确保集群拥有足够的硬件资源,如内存和CPU,是保障优化效果的基础,特别是在使用内存密集型的Map Join时,充足的内存至关重要。
调整并行度:通过调整Map和Reduce任务的数量,可以优化作业的并行度,过多的并行任务可能会增加资源的占用和调度开销,而过少则不能充分利用集群资源。
这些优化策略的实施,不仅需要对Hive和Hadoop有深入的了解,还需要根据实际的数据特征和业务需求灵活应用,优化过程中可能遇到的问题和对策包括但不限于以下方面:
监控和调优任务执行,注意观察任务执行时的系统资源使用情况和日志信息,以便及时发现问题并进行调整。
在进行大规模的JOIN操作前,先对数据进行抽样测试,评估不同优化策略的效果。
可能还需考虑如数据更新频率、查询复杂度等因素,结合实际情况制定最佳实践方案,比如在一些场景下,可能需要权衡内存消耗和查询性能之间的关系,确定最合适的JOIN策略和配置。
相关问答FAQs:
Q1: 什么情况下推荐使用Map Join?
A1: 当一张小表需要与一张大表进行JOIN操作时,推荐使用Map Join,因为这样可以将小表加载到内存中,避免了Reduce阶段的开销,特别适用于小表和大表之间的连接。
Q2: 如果遇到数据倾斜应该如何优化?
A2: 数据倾斜通常会导致某些Reduce任务处理的数据量异常庞大,可以通过Range分区或者事先进行数据采样分析KEY的分布情况,据此采取适当的负载均衡措施,例如调整Reducer的数量或手动设置分区。
优化Hive中的Join操作是一项复杂而重要的工作,它关系到数据处理的效率和响应时间,通过使用Map Join、合理设计表的存储格式和分区、选择合适的Join算法、优化数据倾斜问题以及合理配置硬件资源和调整并行度等方法,可以有效提升Hive处理大规模数据集的能力,这些优化措施并不是孤立的,它们需要根据具体的数据特性和业务需求综合运用,以达到最佳的性能表现。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/950960.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复