


在当今大数据时代,MapReduce作为一种强大的分布式计算模型,广泛应用于处理海量数据的场景中,通过将计算任务分发到多个节点上并行处理,MapReduce能有效提高数据处理速度和效率,在实际的应用过程中,如何对MapReduce程序进行有效的分析和调优,成为提升性能的关键所在,下面将结合实际案例,深入探讨MapReduce的调优策略。


MapReduce调优重要性
在讨论具体的调优案例之前,理解为何需要对MapReduce进行调优至关重要,MapReduce虽然强大,但在默认配置下并不一定能达到最优的性能表现,诸如作业执行时间过长、资源利用不均等问题,都可能导致处理效率低下,通过调整参数配置、优化算法逻辑等方式来提升性能,对于满足业务需求、提高资源利用率具有重要意义。
实际调优案例分析
案例一:优化MapReduce作业执行时间
在一个大型电商平台的用户行为分析项目中,数据团队使用MapReduce处理每天产生的数TB日志数据,初始时,作业执行时间长达数小时,远远无法满足实时分析的需求,通过对作业进行分析,团队发现主要的瓶颈在于Map阶段和Reduce阶段的数据倾斜问题。
1、Map阶段优化:原作业中,Map任务处理的数据分布极不均匀,导致部分Map任务执行时间远超其他任务,针对这一问题,团队采用了Map端的数据预处理技术,如实施合理的数据分区,确保每个Map任务处理的数据量相对平衡。
2、Reduce阶段优化:由于Reduce阶段需要等待所有Map任务完成后才能开始,团队通过调整Reduce阶段的任务数量,减少单个Reduce任务的处理负担,同时采用Combiner来局部聚合Map输出,减少数据传输量。
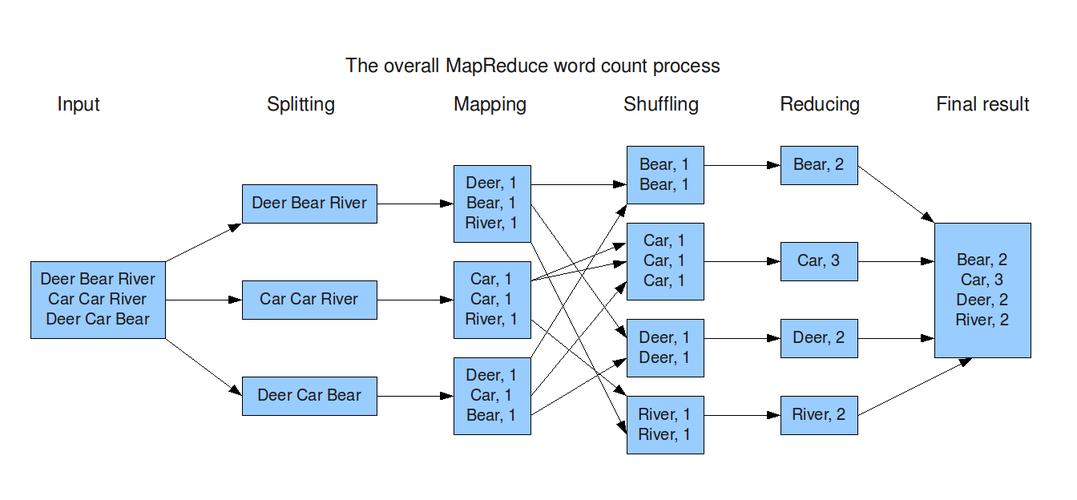
通过上述优化措施,该项目的MapReduce作业执行时间从数小时缩短至几十分钟,极大提升了数据处理的效率和响应速度。
案例二:优化资源利用率
在一次大数据分析项目中,团队成员注意到,尽管MapReduce作业能够顺利完成,但是集群的资源利用率并不理想,具体表现为部分节点的CPU和内存资源在作业执行期间长时间处于低负载状态。
1、资源分配策略调整:为了解决资源利用不均的问题,团队首先分析了不同节点上任务的资源需求,根据任务的实际需求动态调整容器的资源大小,确保每个节点都能高效运作。
2、优化作业调度:通过引入更为灵活的作业调度策略,比如FIFO、Capacity Scheduler以及Fair Scheduler等,使得资源分配更加合理,避免了资源的浪费和任务的拖延。
通过这些优化措施,不仅提高了集群的整体资源利用率,还在一定程度上降低了作业的执行成本,实现了更经济高效的数据分析处理。
调优技巧归纳

从以上案例可以看出,MapReduce的性能调优是一个涉及多方面考虑的过程,以下是一些通用的调优技巧:
合理设置Map和Reduce的数量:根据数据集的大小和结构,合理设定Map和Reduce任务的数量,可以有效平衡负载,提升处理速度。
数据倾斜处理:识别并解决数据倾斜问题,保证任务的均衡分配,避免个别任务成为性能瓶颈。
合理使用Combiner和InMemory Compression:使用Combiner减少数据在网络中的传输量,应用内存压缩技术优化内存使用,进一步提高性能。
优化数据读写:优化数据的读写方式,比如使用序列化技术减少数据大小,加快数据传输速度。
相关问答FAQs
Q1: MapReduce调优是否意味着只是改进代码和配置?
A1: 不仅仅是,虽然改进代码和调整配置是MapReduce调优的重要组成部分,但也包括了对数据分布、硬件资源的深入理解和优化,还需考虑到网络条件、存储系统的性能等因素。
Q2: 如何判断我的MapReduce作业是否需要调优?
A2: 如果你的MapReduce作业运行时间远超预期,或者集群资源利用率不高,又或者作业频繁失败等问题出现,这些都可能是需要进行调优的信号,监控和记录作业的运行状态,对比预期目标和实际表现,有助于识别是否需要调优。
通过上述案例分析和调优技巧的归纳,可以看到MapReduce调优是一个复杂但极其重要的过程,它不仅涉及到软件层面的优化,如代码改进、配置调整,还包括对硬件资源、数据特性等方面的深入理解和应用,正确的调优策略能显著提高MapReduce作业的执行效率和资源利用率,为企业带来更大的技术价值和经济效益。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/950425.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复