


在探讨MapReduce Job数量与配置其基线的问题上,需要理解MapReduce的工作原理,MapReduce是Hadoop框架中用于处理大规模数据集的编程模型,其中包含两个主要的组件:Mapper和Reducer,本文将深入分析如何根据实际需求合理配置MapReduce Job的数量,以及如何设定一个合理的基线,确保系统性能的最优化。
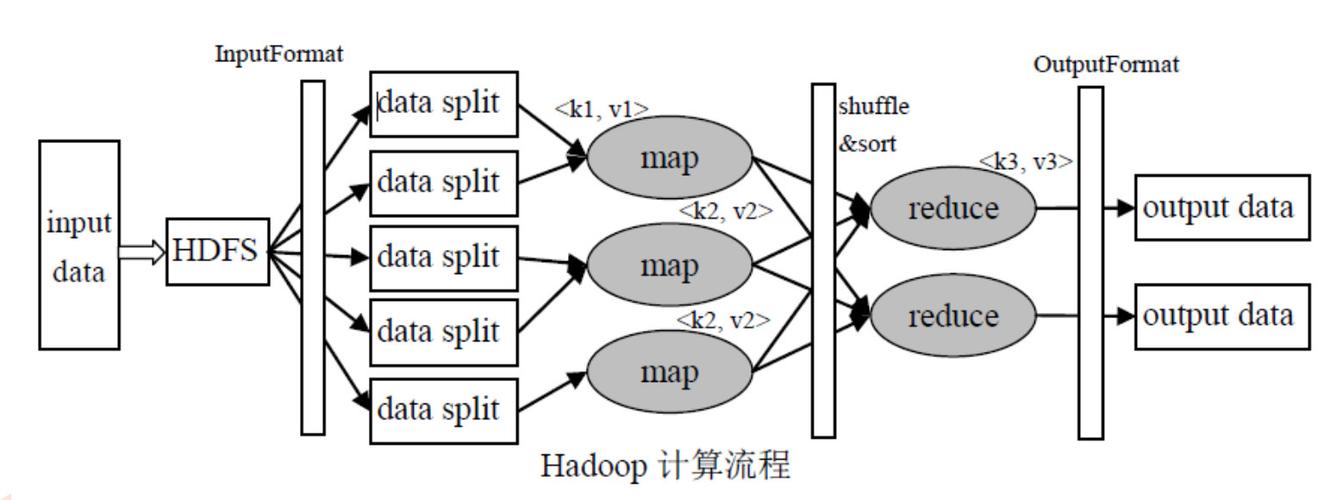

Mapper和Reducer的角色
1、Mapper的角色
数据读取:Mapper负责从Hadoop分布式文件系统(HDFS)中读取数据文件。
数据处理:数据被解析成键值对,通过用户定义的map方法进行处理,然后输出中间的键值对。
效率优化:Mapper任务的处理过程分为多个阶段,每个阶段的优化都直接影响到作业的整体效率。
2、Reducer的职责
数据整合:Reducer接收来自Mapper的输出,并将其作为输入数据。
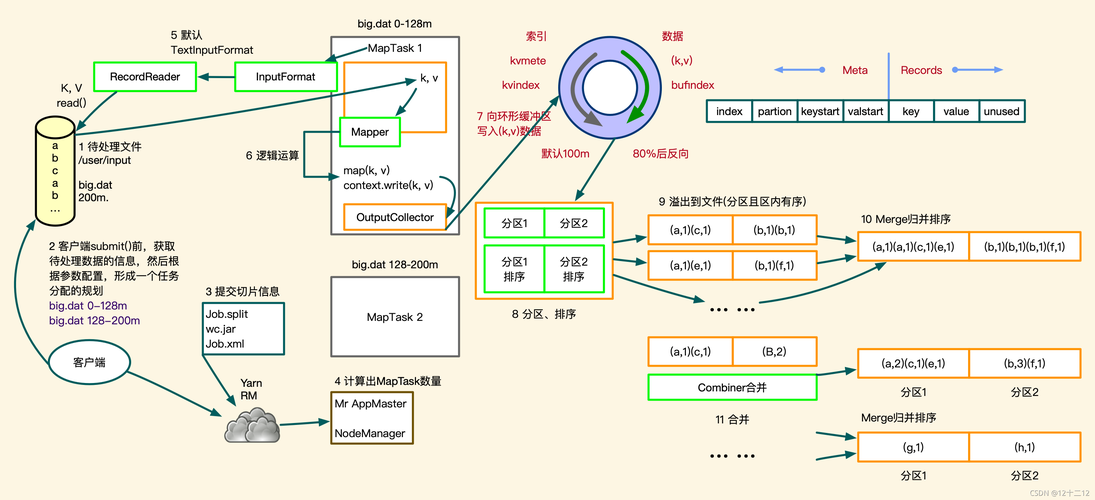
最终输出:经过用户定义的reduce方法处理后,Reducer将结果输出到HDFS的文件中。
负载分配:合理配置Reducer的数量可以有效地平衡工作负载,避免数据倾斜问题。
MapReduce Job数量的配置
1、数据大小考虑
分片标准:输入文件的大小决定了Mapper任务的数量,每个输入片的大小通常是固定的。
并行处理:较大的数据集需要更多的Mapper和Reducer任务以实现并行处理,缩短作业完成时间。
2、硬件资源限制
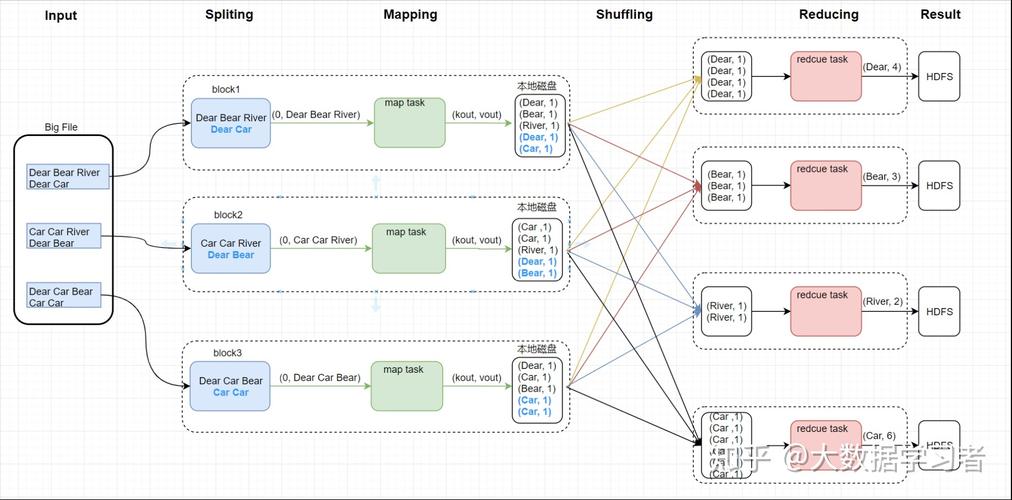
资源利用:可用的CPU和内存资源限制了可以同时运行的Mapper和Reducer任务的数量。
磁盘I/O:过多的并发任务可能会导致磁盘I/O竞争,影响性能。
3、作业类型的影响
CPU密集型:对于计算密集型作业,可能需增加Mapper和Reducer的数量以提高并行度。
I/O密集型:对于I/O密集型作业,优化数据读取和写入的效率更为关键。
4、容错机制的设计
失败恢复:MapReduce通过重新执行失败的任务来保证作业的成功完成。
备份任务:设置一定数量的备份任务可以加快失败任务的恢复速度。
基线配置的策略
1、性能测试
基准测试:通过运行典型作业负载进行性能测试,确定最优的Job数量配置。
监控指标:关注CPU使用率、磁盘I/O等指标,评估不同配置下的性能表现。
2、动态调整
自适应调整:根据作业的实时运行情况动态调整Job数量。
预测模型:利用历史数据建立预测模型,预估不同配置下的性能表现。
3、经验规则
经验数值:根据经验,为特定类型的作业设定一个初始的Job数量基线。
持续优化:随着集群环境和作业特性的变化,不断调整基线配置。
性能优化的实践
1、数据预处理
格式优化:优化数据的存储格式,减少Mapper任务的解析负担。
数据本地化:尽量让数据在本地处理,减少网络传输开销。
2、代码优化
算法优化:优化map和reduce函数中的算法逻辑,提高数据处理效率。
内存管理:合理管理内存资源,避免内存溢出等问题。
3、调度策略
公平调度:通过公平调度器确保各个作业公平共享资源。
容量调度:容量调度器可以为不同的作业分配一定的资源容量。
相关FAQs
1. 如何确定MapReduce作业的最佳并发数?
答:确定最佳并发数需要考虑数据大小、硬件资源、作业类型等多个因素,可以通过性能测试和监控指标来评估不同并发数下的性能表现,从而找到最佳的配置点。
2. MapReduce作业失败时,有哪些恢复策略?
答:MapReduce框架提供了失败恢复机制,包括重新执行失败的任务和设置备份任务,还可以通过优化代码和资源配置来减少作业失败的可能性。
通过全面地分析和实践,我们可以得到一个合理的MapReduce Job数量配置和基线设置,以优化整个Hadoop集群的性能,合理的配置不仅能够提高作业的执行效率,还能确保系统的稳定运行,在实际操作中,应结合具体的业务需求和集群环境,动态调整配置策略,以达到最佳的性能表现。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/948748.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复