


在计算机科学和编程中,递归查询是一种算法设计方法,其中函数或算法直接或间接地调用自己以解决更小的问题实例,递归查询通常涉及将一个问题分解为更小的子问题,直到达到一个足够小的问题可以直接解决的情况,即基本情况。
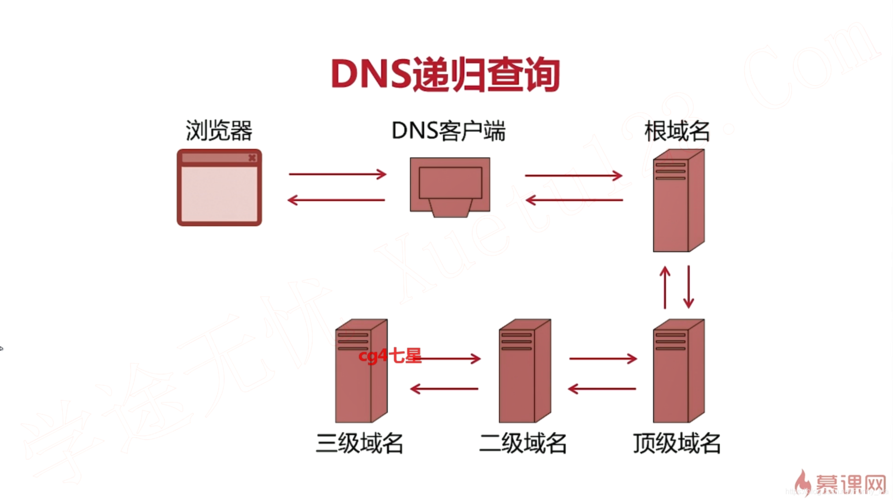

递归查询的概念
递归查询的基本思想是将复杂的问题分解成可以逐个解决的小问题,递归查询通常包括两个主要部分:基本情况(base case)和递归情况(recursive case),基本情况是问题的最简单形式,可以直接解答而不需要进一步的递归,递归情况包含了对自身的调用,用于解决更复杂的问题实例。
递归查询的工作原理
1、确定基本情况:这是递归结束的条件,通常是问题规模最小的实例,可以直接给出答案。
2、定义递归关系:描述如何通过解决较小的问题来解决问题的一个较大实例。
3、设计递归函数:编写一个函数来实现递归逻辑,该函数应能够处理基本情况和递归情况。
4、执行递归查询:函数开始执行,每次调用自身时都减小问题的规模,直至达到基本情况为止。
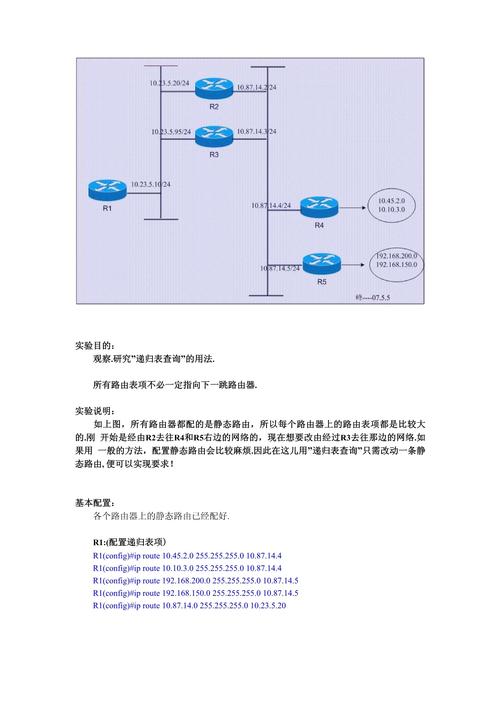
5、合并结果:将递归调用的结果组合起来得到最终答案。
递归查询的优势与风险
优势:
简化问题解决过程:递归可以将复杂问题转化为更易于理解和解决的简单问题。
代码简洁性:递归查询可以使代码更加简洁、易读,尤其是对于分治策略的问题。
自然映射:许多数学和自然界的问题都是递归的,使用递归查询可以很自然地表达这些问题。
风险:
性能问题:递归可能导致大量的函数调用,从而消耗更多的内存和计算资源。
栈溢出:深度递归可能导致调用栈溢出,因为每次递归调用都会占用栈空间。
调试难度:递归算法可能难以调试,特别是在递归深度很大的情况下。
使用场景
递归查询在许多编程和算法问题中非常有用,
树和图遍历:如深度优先搜索(DFS)和广度优先搜索(BFS)。
动态规划:解决具有重叠子问题和最优子结构特性的问题。
分治算法:如归并排序和快速排序,它们将问题分解为更小的部分,然后合并结果。
数学问题:如计算阶乘、斐波那契数列等。
相关问答FAQs
Q1: 递归查询是否总是最有效的解决方案?
A1: 不一定,虽然递归查询在某些情况下可以提供简洁和直观的解决方案,但它可能导致效率低下,尤其是在递归深度大或者问题规模大的时候,递归查询可能会导致大量的函数调用开销和栈空间的使用,有时迭代方法或者其他算法技巧可能更有效。
Q2: 如何避免递归查询中的栈溢出问题?
A2: 栈溢出通常是由于递归深度过大导致的,为了避免这个问题,可以采取以下措施:
优化算法以减少递归深度。
使用尾递归优化(如果编程语言支持)来减少栈的使用。
将递归转换为迭代,使用显式的栈结构来管理状态。
增加程序的栈大小限制(如果可行),但这应该作为最后的手段,因为它不能根本解决问题,只是推迟了问题的发生。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/947132.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复