


python,def default_copy(input_str):, return input_str,`,,使用这个函数时,只需将要拷贝的内容作为参数传入即可。,,`python,result = default_copy("0"),print(result) # 输出:0,“在C++编程中,拷贝构造函数是类的一个特殊成员函数,用于创建一个对象作为另一个同类型对象的副本,当在类定义中没有显式地声明拷贝构造函数时,编译器会自动为类生成一个默认的拷贝构造函数,本文将详细探讨默认拷贝构造函数的功能和作用,以及它在C++程序设计中的应用。

默认拷贝构造函数的基本概念
当一个类没有显式定义拷贝构造函数时,C++编译器会自行提供一个默认的拷贝构造函数,这个自动生成的函数通常执行浅拷贝操作,即直接复制对象的每个成员变量的值,这种拷贝方式简单高效,适用于大多数简单的数据类型。
默认拷贝构造函数的工作机制
默认拷贝构造函数的工作原理类似于C语言中的变量赋值,在C++中,如果一个类没有自定义的拷贝构造函数,编译器就会介入,自动添加一个默认拷贝构造函数,使得一个类的实例可以被直接初始化或赋值为另一个实例的副本。
默认拷贝构造函数与浅拷贝
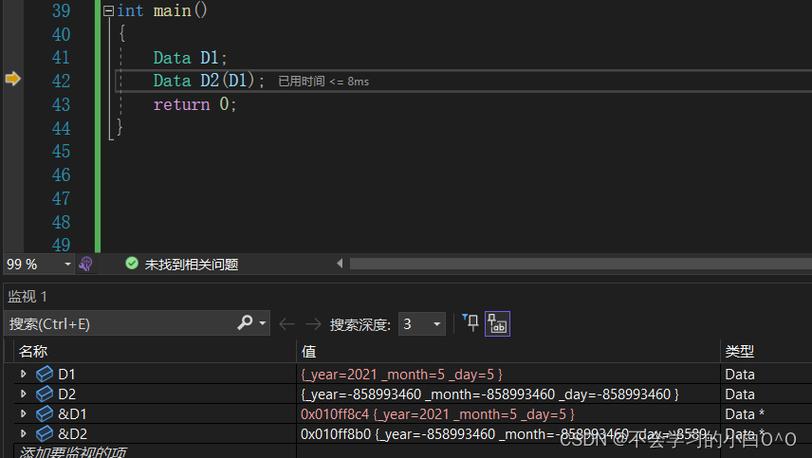
默认拷贝构造函数执行的是浅拷贝,这意味着如果类的成员中包含指向动态内存的指针,那么拷贝后的对象与原对象将共享同一块内存区域,这在某些情况下可能导致意外的行为,比如当其中一个对象被析构时,可能会释放掉另一个对象仍在使用的内存。
默认拷贝构造函数的限制
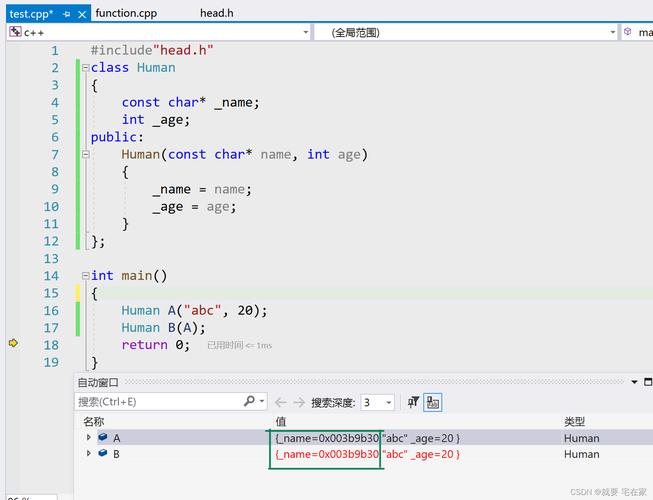
虽然默认拷贝构造函数在很多情况下都能良好工作,但对于涉及复杂资源管理需求的类来说,它可能不适用,含有动态分配内存的类、需要深拷贝的类或者单例模式的类等,都需要自定义拷贝构造函数以实现正确的资源管理和拷贝行为。
自定义拷贝构造函数的必要性
对于涉及深拷贝或有特殊拷贝需求的情况,开发者应该自定义拷贝构造函数,自定义拷贝构造函数可以精确控制拷贝过程,避免浅拷贝带来的问题,确保每一个对象都有其独立的资源副本,从而保证程序的正确性和稳定性。
默认拷贝构造函数的应用场景
默认拷贝构造函数通常用于:通过使用另一个同类型的对象来初始化新创建的对象;复制对象并把它作为参数传递给函数;从函数返回复制的对象,这些操作在不需要特别处理资源管理的简单数据类型中非常常见。
默认拷贝构造函数是C++中一个非常重要的特性,它提供了一种简便的方式来创建对象的副本,虽然它主要执行浅拷贝,但了解其工作原理和限制可以帮助开发者更好地利用这一特性,并在必要时编写合适的自定义拷贝构造函数,以确保程序的正确性和效率,让我们通过一些常见问题进一步加深对默认拷贝构造函数的理解。
相关问答FAQs
Q1: 默认拷贝构造函数和自定义拷贝构造函数有什么区别?
A1: 默认拷贝构造函数由编译器自动生成,执行浅拷贝,适用于简单的数据类型和不需要特别资源管理的场景,而自定义拷贝构造函数允许开发者定义特定的拷贝逻辑,如深拷贝,这对于涉及动态内存分配或复杂资源管理的类来说是必要的。
Q2: 如何决定是否需要自定义拷贝构造函数?
A2: 如果一个类只包含基本类型或简单的复合类型,并且没有特殊的资源管理需求(如动态内存分配),则可以使用默认的拷贝构造函数,相反,如果类需要管理复杂的资源,如动态内存、文件句柄或其他需要独立管理的资源,则应自定义拷贝构造函数以确保正确和安全的拷贝过程。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/946964.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复