


HTML格式转换为TXT格式的全面指南

在信息技术快速发展的今天,数据转换已成为日常工作中常见的需求之一,特别是对于Web开发者和内容管理者来说,将HTML格式转换为TXT格式是一种常见的需求,用于提取网页内容、生成报告或进行数据分析,本文将详细介绍如何从HTML格式转换到TXT格式,包括使用不同的工具和方法,以确保读者能够根据自己的需求选择最合适的转换方式。
理解HTML与TXT的区别
了解HTML(HyperText Markup Language)和TXT(Plain Text)之间的基本区别是重要的,HTML是一种用于创建网页的标记语言,它包含文本内容以及描述页面元素的标签,如标题、段落、链接等,相反,TXT格式只包含纯文本信息,没有任何格式或样式元素。
为何需要转换?
转换HTML到TXT的需求通常来源于以下几个方面:
阅读:移除所有HTML标签,只保留文本内容,便于阅读和编辑。
数据分析:为了进行文本分析或数据挖掘,需要将HTML文档转换为更易于处理的TXT格式。
存档:出于存档目的,许多组织倾向于保存纯文本文件,因为它们占用空间小且兼容性高。
转换方法
手动复制粘贴
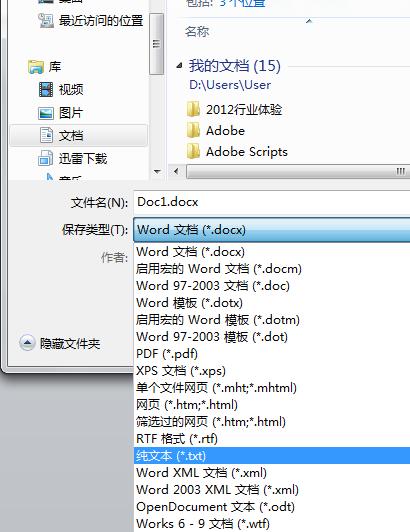
最简单的方法是直接从HTML文件中复制文本内容,然后粘贴到文本编辑器中保存为TXT文件,这种方法适用于内容量不大的情况,但效率低,不适用于大量文件的转换。
使用在线转换工具
网络上有许多免费的在线工具可以快速将HTML转换为TXT,这些工具通常只需要上传HTML文件,然后自动去除HTML标签,提供下载TXT文件的选项。“Online HTML to TXT Converter”是一个用户友好的在线工具,支持批量转换。
编程方法
对于开发者来说,通过编程实现HTML到TXT的转换提供了更大的灵活性和自动化能力,以下是使用Python进行转换的简单示例:
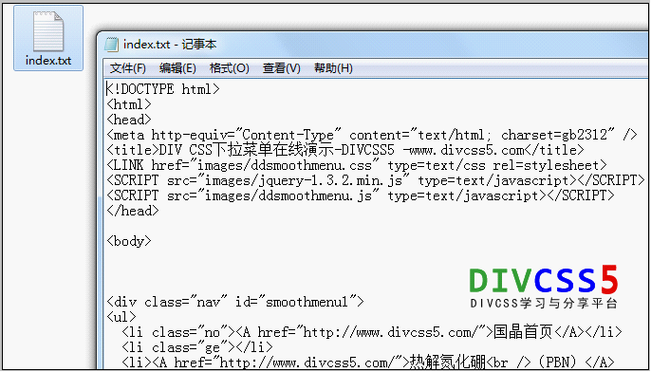
from bs4 import BeautifulSoup def html_to_txt(html_content): soup = BeautifulSoup(html_content, 'html.parser') text = soup.get_text() return text html_content = "<html><head><title>测试页面</title></head><body><p>这是一段HTML内容。</p></body></html>" txt_content = html_to_txt(html_content) print(txt_content)
此代码使用了BeautifulSoup库来解析HTML内容并提取纯文本,这种方式适合需要定制化处理或自动化处理多个文件的场景。
高级工具和软件
对于更为复杂的转换需求,市面上也提供了多种高级工具和软件,如Adobe Acrobat、Pandoc等,它们不仅支持HTML到TXT的转换,还支持多种文件格式之间的转换。
转换后的处理
转换完成后,你可能还需要对TXT文件进行进一步处理,比如去除多余的空白字符、调整换行符等,以确保文本内容的整洁和一致性,大多数文本编辑器都提供了这些基本的文本处理功能。
相关问答FAQs
Q1: 转换后的TXT文件大小会显著减小吗?
A1: 是的,由于去除了HTML标签和格式信息,TXT文件通常会比原始HTML文件小很多,这也使得TXT文件更易于存储和传输。
Q2: 转换过程中会不会丢失重要信息?
A2: 转换过程主要是去除HTML标签,所以纯文本内容本身不会丢失,需要注意的是,一些格式化信息(如粗体、斜体)和超链接等HTML特有的元素在TXT文件中无法保留,这可能会影响到文本的阅读体验和信息的完整性,在转换前应考虑这些因素,确保转换结果符合你的需求。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/944539.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复