


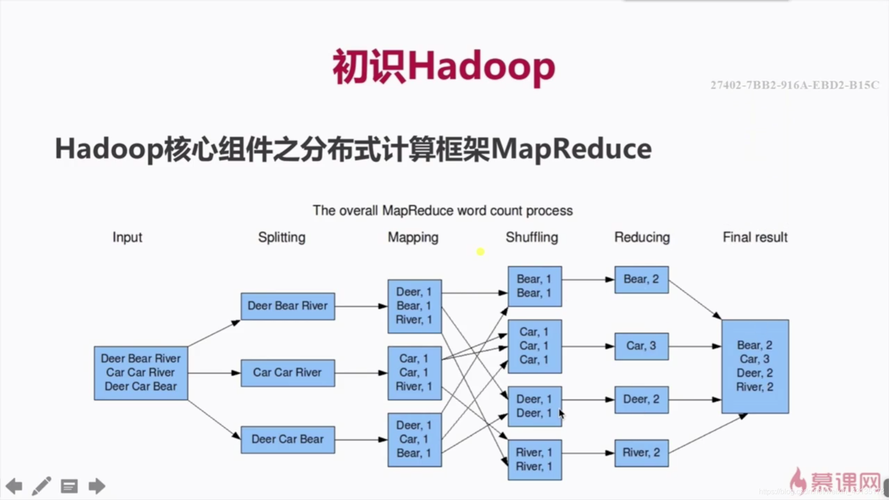
在处理大数据时,Hadoop和HBase是两种关键技术,Hadoop的MapReduce框架用于大规模数据集的并行处理,而HBase则是一个分布式、可伸缩的大数据存储,本文将深入探讨如何通过MapReduce生成HFile,并将这些文件迁移到HBase中以实现索引数据的高效管理,这一过程不仅优化了数据处理速度,还提高了数据导入的效率,特别适合于大量数据的快速迁移和处理。

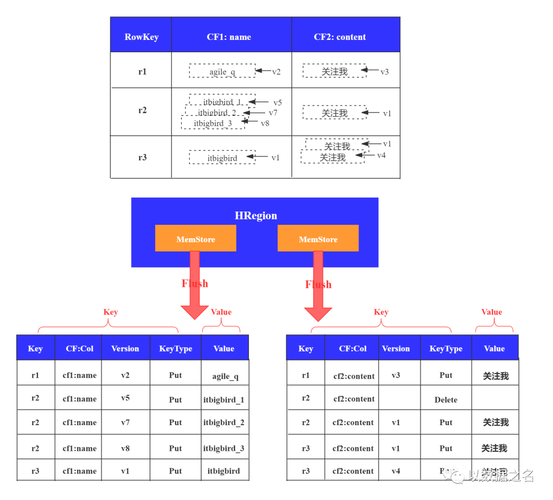
理解HFile的生成是关键步骤,HFile是HBase的文件存储格式,它直接影响数据如何被存储和读取,通过使用MapReduce程序,可以有效地将原始数据转换成HFile格式,此过程中,Map函数负责读取原始数据并转换为键值对,而Reduce函数则将这些键值对写入到HFile文件中,具体操作包括设置合适的数据结构以及配置输出格式为HFile。
生成的HFile需要被加载到HBase中,有几种方法可以实现这一点,其中BulkLoad是一种高效的批量加载方式,BulkLoad跳过了HBase的写前日志(WAL)验证,直接将HFile加载到表中,这大大加快了数据加载的速度,使用HBase的客户端API,如Table.put方法,也可以将数据写入HBase,虽然这种方法在处理大量数据时效率不如BulkLoad。
实际操作中,生成和加载HFile的过程中涉及到多个技术细节,选择合适的压缩算法可以在减少存储空间的同时提高读写效率,常用的压缩算法包括Gzip、LZO等,合理配置MapReduce的并发度和内存使用参数,可以进一步优化处理速度和资源利用率。
数据一致性和错误处理也是重要的考虑因素,在数据转换和加载过程中可能会遇到数据损坏或格式不一致的问题,实现良好的错误检测和恢复机制是确保数据完整性的关键,可以在MapReduce作业中添加自定义的校验和清理步骤,以剔除不合规的数据记录。
在实际操作中,监控和调试工具的使用也非常重要,利用Hadoop和HBase提供的Web界面或命令行工具,可以实时监控数据处理的状态和性能指标,及时发现并解决潜在的问题。
考虑到不同版本之间的兼容性问题,选择合适的Hadoop和HBase版本对于保证整个过程顺利进行至关重要,根据已有的案例和文档,建议选择稳定且广泛支持的版本组合,如Hadoop 2.7.7与HBase 2.0.5,以确保最大程度的兼容性和社区支持。
相关问答FAQs
1. 为什么使用MapReduce生成HFile比直接写入HBase更高效?
使用MapReduce生成HFile之所以更高效,主要是因为这种方式可以利用分布式计算框架并行处理数据,大幅减少数据处理时间,通过BulkLoad将HFile加载到HBase中可以跳过耗时的WAL验证过程,进一步提高数据加载速度。
2. 如何处理在生成HFile或加载到HBase过程中出现的数据错误?
在生成HFile或加载到HBase的过程中,可以通过实现错误检测机制来识别数据错误,如添加数据校验码和进行格式验证,对于检测到的错误数据,可以选择记录日志、发送通知或尝试自动修复,具体策略根据数据的重要性和错误类型灵活调整。
通过上述步骤和策略,可以有效地利用MapReduce生成HFile并迁移至HBase,实现大规模数据集的高效管理和分析,这不仅提高了数据处理的速度和效率,也为复杂数据分析提供了坚实的基础。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/943386.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复