

提升Hadoop性能的关键
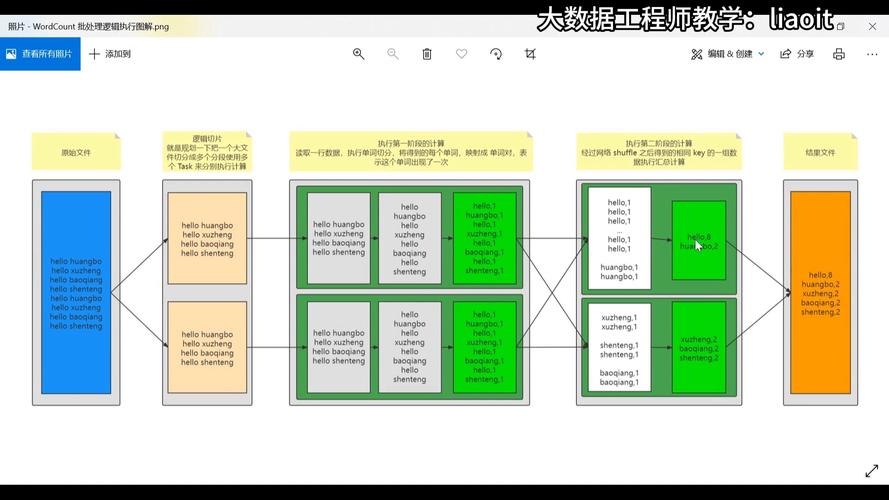

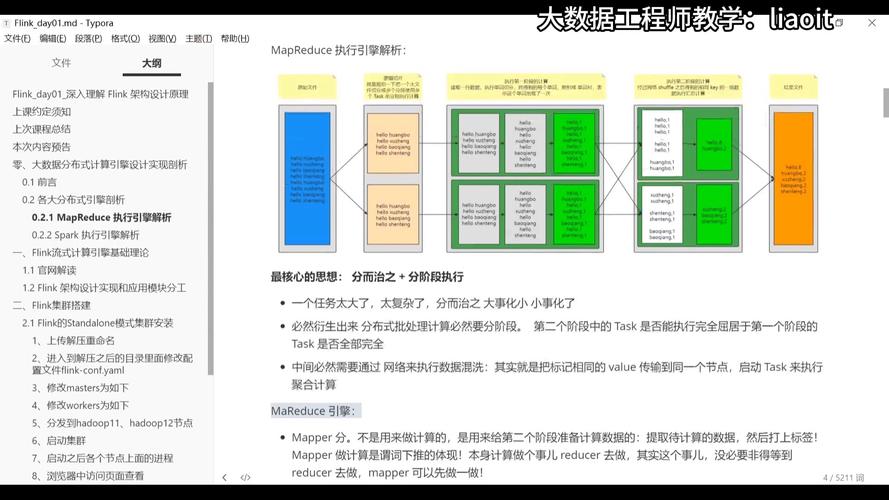
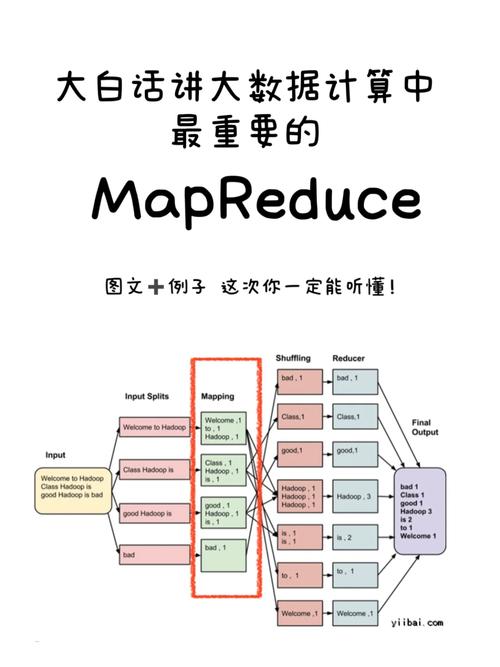
MapReduce数据本地性是Hadoop框架中一个至关重要的概念,它指的是在数据处理时将计算任务尽可能地移至数据存储的节点上执行,避免了大量数据的跨网络传输,了解此概念的本质和优点,对于有效使用Hadoop处理大规模数据集至关重要。
在Hadoop生态系统中,HDFS(Hadoop Distributed File System)负责数据的存储,而MapReduce则处理数据的计算,HDFS将数据分成多个块,这些块分散存储在集群的不同数据节点上,在不涉及数据本地性的传统场景中,如果计算任务处理器需处理的数据不在同一节点上,则需要通过Hadoop网络传输数据至计算节点,这会引起显著的网络延迟和带宽消耗。
数据本地化的优势在于减少了数据传输的需求,数据本地性有三种情况:Data Local、IntraRack和InterRack,Data Local情况下,数据和计算任务在同一节点上执行,这是最理想的状态,IntraRack指数据和计算任务位于同一机架的不同节点上,而InterRack则是数据和计算任务在不同机架上,这两种情况渐次降低了数据处理速度和效率。
利用数据本地性的MapReduce作业能显著提升运算速度和系统的总吞吐量,当数据不需要跨网络进行大规模移动时,每个节点可以更快地完成数据处理任务,从而加速整个作业的完成时间,减少网络使用也能降低整个Hadoop集群的能耗,使得资源使用更加高效。
进行MapReduce作业时,如何优化数据本地性?在作业配置时,可以优先将计算任务调度到数据所在的节点上执行,合理设计数据存储策略,预见性地考虑数据与计算的局部性关系,可以进一步优化数据处理流程,在实际操作中,监控和分析作业执行细节也有助于发现潜在的数据移动热点,以便未来优化。
归纳而言,MapReduce的数据本地性是Hadoop高效运作的核心要素之一,理解并应用数据本地性原则,不仅可以显著提高数据处理速度,还可以最大化资源利用率,降低运维成本,对于任何使用Hadoop的企业或开发者来说,深入掌握这一概念,将是提升大数据处理能力的基石。
相关问答FAQs
为什么数据本地性对Hadoop如此重要?
数据本地性的重要性源于其能够显著减少网络拥堵并加快数据处理速度,在大规模数据处理场景下,通过网络传输大量数据会导致严重的延迟和资源消耗,数据本地性确保了数据和计算任务在同一节点上执行,大幅度降低了数据需要在网络中移动的频率,从而提升了整个系统的效率和响应速度。
如何优化MapReduce作业的数据本地性?
要优化MapReduce作业的数据本地性,首先需要深入理解数据的存储位置和访问模式,在作业调度时,优先选择数据所在节点执行计算任务,可以通过合理的数据预布局和调整网络拓扑结构来减少跨机架的数据访问,持续监控和分析作业执行过程中的数据访问模式,也是不断优化数据本地性策略的重要手段。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/942405.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复