


在当今大数据时代,MapReduce框架作为处理大规模数据集的一种有效手段,其高效性与可靠性已经被广泛认可,MapReduce结构图和组合结构图为理解这一框架的内部机制提供了可视化的工具,我们将深入探讨MapReduce的体系结构和工作流程,以及组合结构图的概念和应用。
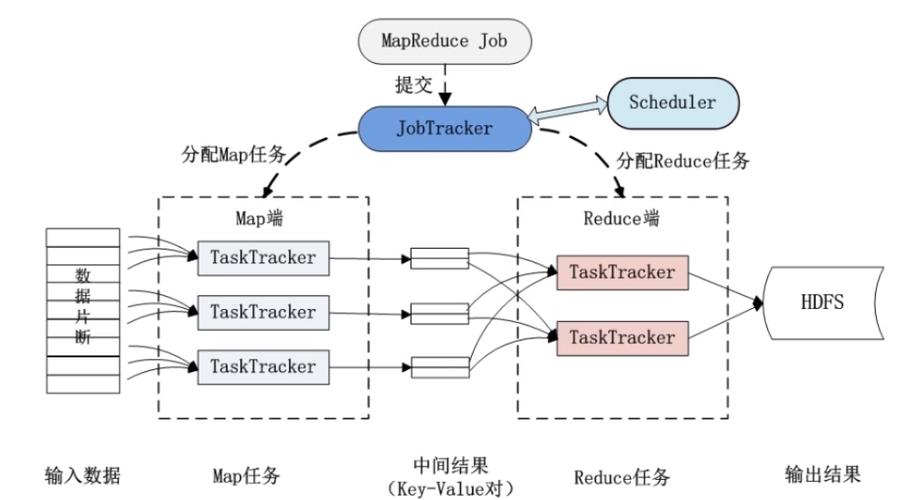

MapReduce 体系结构
MapReduce的体系结构主要由以下四个部分组成:
1、Client:
Client是用户与MapReduce系统交互的界面,用户通过它提交作业。
Client提供了操作接口,用户可以借此查看作业运行状态。
2、JobTracker:
JobTracker负责资源监控、作业调度,并持续跟踪所有TaskTracker和作业的健康状态。
当TaskTracker或作业出现失败时,JobTracker负责将任务迁移到其他节点以保证作业的正常执行。
3、TaskTracker:
TaskTracker向JobTracker报告资源使用情况和作业运行状态。
它接受来自JobTracker的命令并执行相应的操作。
4、Task:
Task分为Map Task和Reduce Task两种类型,都是实际执行作业任务的单位。
它们由TaskTracker启动,并根据指令执行映射或归约操作。
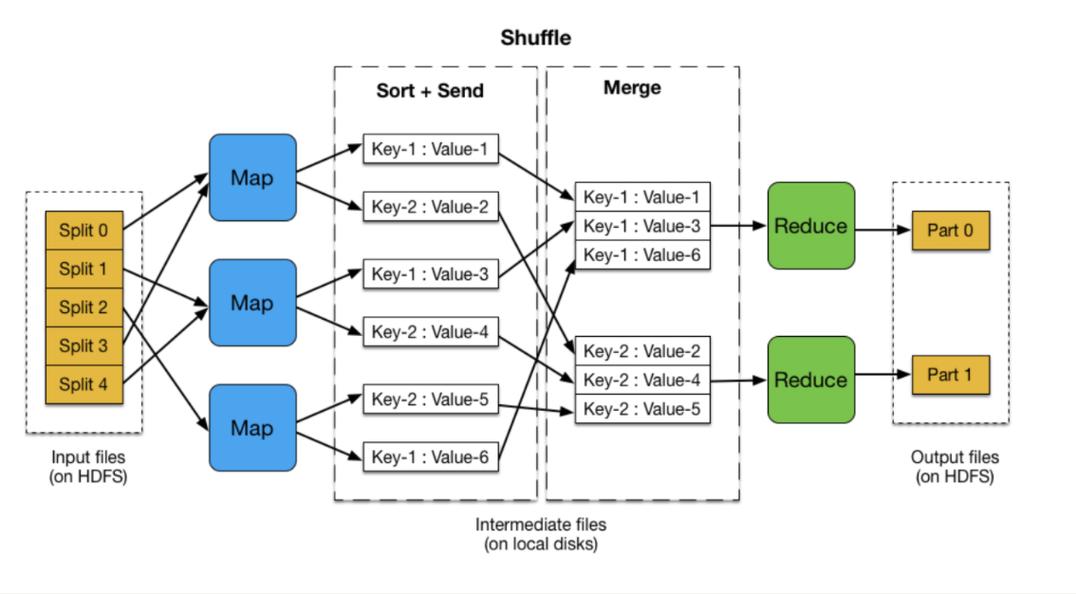
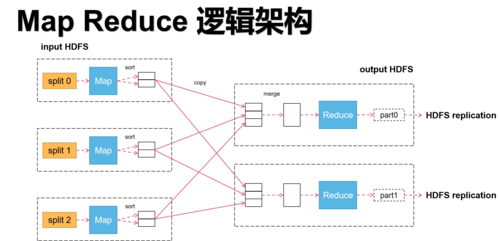
MapReduce 工作流程
MapReduce的工作流程大致可以分为三个主要阶段:
1、Shuffle阶段:
这一阶段涉及从远程节点读取Map Task的中间结果。
中间结果会根据key值进行排序,为下一阶段做准备。
2、Sort阶段:
该阶段对数据根据key进行排序,确保相同key的值聚集在一起。
这是为了提高Reduce阶段的效率。
3、Reduce阶段:
这个阶段将处理排序后的数据,并将其传递给用户定义的Reduce函数。
最终的结果将会被存储到HDFS(Hadoop分布式文件系统)上。
组合结构图
组合结构图是一种静态结构图,用于描述系统中某一部分的内部结构及其与其他部分的交互点,这种图表能够展示内容“内部”参与者的配置情况,有助于我们理解系统内部的协作和流程。
MapReduce框架的高效处理能力得益于其严谨的体系结构和清晰的工作流程,而组合结构图则为理解这一框架的内部机制提供了一种图形化的视角,这些工具和概念的结合,不仅加深了我们对数据处理框架的理解,还帮助我们更好地把握大数据技术的应用与发展,我们将通过一些常见问题及答案来加深理解。
FAQs
什么是MapReduce中的Shuffle阶段?
*Shuffle阶段是MapReduce工作流程中的一个重要部分,它负责从各个Map Task所在的远程节点上读取中间结果,这个阶段包括对中间结果的收集和对key进行排序,准备数据供Reduce阶段使用。
如何理解组合结构图的作用?
*组合结构图描述了系统中特定部分的内部结构及其与系统其他部分的交互点,它展示了该部分内部的参与者配置情况,帮助开发者和使用者理解系统内部的组织结构和运作方式。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/940649.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复