

python,def mapper():, for line in input_data:, data = line.split("t"), if len(data) > 12:, key = (data[4], data[5]), value = int(data[10]), yield key, value,`,,这段代码定义了一个名为mapper`的函数,它从输入数据中读取每一行,并将其拆分为一个列表。它检查列表的长度是否大于12,如果是,则提取第5和第6个元素作为键(key),将第11个元素转换为整数作为值(value)。它生成一个键值对并返回。MapReduce是处理大规模数据集的编程模型,它通过两个核心阶段——Map和Reduce,实现了数据的分布式处理,下面将详细探讨如何在Mapper中使用Key,并分享一些MapReduce的统计样例代码来帮助理解其实际应用,具体分析如下:

1、MapReduce的基础概念
MapReduce简介: MapReduce是一个计算模型,用于在Hadoop平台上进行大规模数据处理,它将计算过程分为两个阶段:Map和Reduce,每个阶段都由大量的方法组成,这些方法并行处理数据,以提高计算速度和效率。
核心组成: 如前所述,Hadoop主要由两部分组成:HDFS(Hadoop Distributed FileSystem)和MapReduce,HDFS提供存储服务,而MapReduce提供计算服务,两者配合使用,可以有效地处理分布在不同物理位置的数据。
2、Mapper的关键作用
数据输入: Mapper的任务是接收原始数据作为输入,并产生一系列中间键值对,在这个过程中,Mapper会对每个输入数据项应用Map函数,生成新的键值对。
Key的角色: 在Mapper中,Key的设计至关重要,Key用于标识数据项,并且参与到后续的数据分组和排序过程,选择合适的Key能够优化数据处理流程,提高整体性能。
3、MapReduce中Key的设计策略
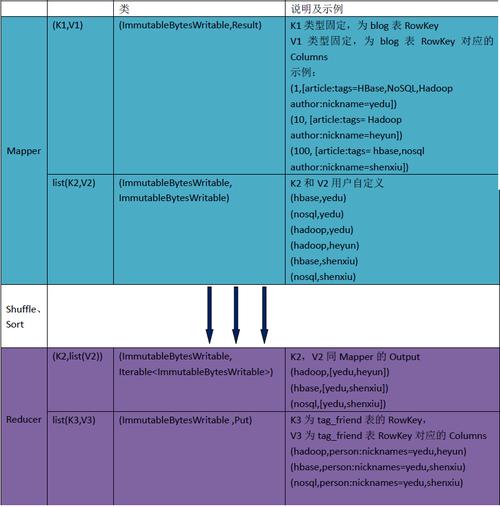
合理选择Key: Key应能准确反映数据特征,便于后续的数据处理,如果任务需要对某个属性进行排序,那么这个属性就是一个好的Key选择,因为MapReduce可以为Key提供默认的排序行为。
考虑数据类型: 当需求为正序且数据类型是Hadoop的基本类型时,可以直接使用这些基本类型作为Key,无需额外修改。
4、MapReduce的编程实践
编程基础: 编写MapReduce程序首先需要了解Hadoop的数据类型、输入输出格式等基础知识,这包括如何定义Mapper和Reducer类,以及如何设置InputFormat和OutputFormat。
实例分析: 在WordCount案例中,Map阶段读取文本文件并将每一行拆分成单词,每个单词作为Key,其出现的次数作为Value,Reduce阶段则对所有相同的Key进行汇总,得出每个单词的总出现次数。
5、实际案例分享
案例一: 考虑到一个大型电子商务平台想要统计每位买家的购买总额,这里,可以将买家ID设为Key,每次购买金额作为Value,通过Map函数处理每次交易记录,然后用Reduce函数对所有相同买家ID的购买金额进行累加。
案例二: 假设一个网站需要统计每个页面的访问次数以分析用户行为,可以将网页URL作为Key,每次访问标记为Value,Map函数负责解析日志文件中的每次页面访问,Reduce函数则累计同一URL的访问次数。
将讨论一些与MapReduce相关的高级技巧和常见问题:
高级技巧: 使用合适的数据结构作为Key可以显著提升性能,若数据集较大且Key的值范围较小,可以考虑使用枚举或固定大小的数组来优化内存使用和处理速度。
常见问题解答:
Q1: 如果数据中的Key分布不均匀怎么办?
A1: 可以尝试复合Key或使用Map阶段的partitioner来控制数据分配,从而平衡各个Reducer的负载。
MapReduce模型通过Map和Reduce两个阶段高效处理大规模数据,在实际应用中,合理设计Key对于提升数据处理效率和精确度非常关键,通过上述案例和技巧的讨论,希望读者能够更好地理解和应用MapReduce框架。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/939864.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复