


MapReduce算法与排序

MapReduce是一种编程模型,用于处理和生成大数据集的并行算法,它由两个阶段组成:Map阶段和Reduce阶段,在Map阶段,输入数据被分割成多个独立的块,然后每个块被映射到一个键值对上,在Reduce阶段,所有具有相同键的值被组合在一起进行处理。
排序
排序是MapReduce中常见的操作之一,通过使用MapReduce进行排序,我们可以有效地处理大规模数据集,并得到一个有序的结果集,下面是一个基本的MapReduce排序算法的步骤:
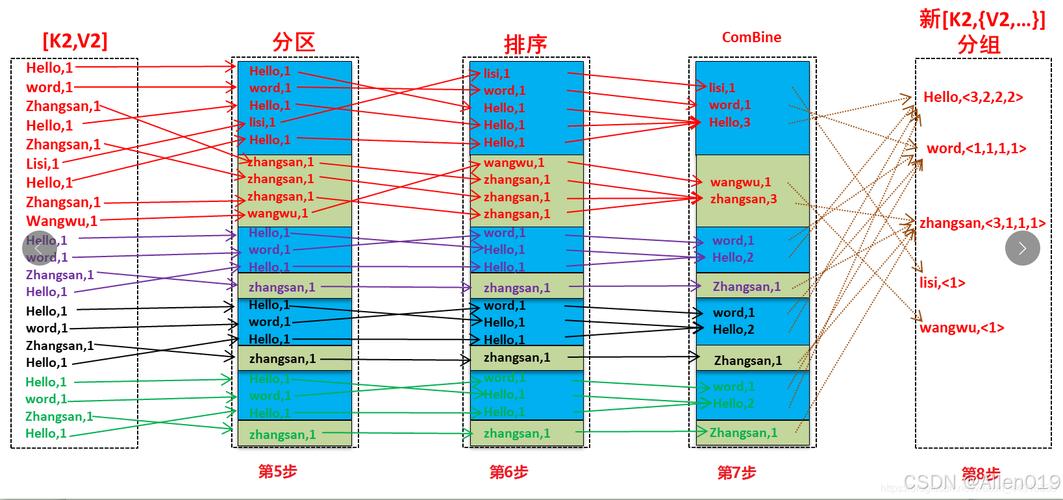
1、Map阶段: 将输入数据分成多个键值对,其中键是要排序的关键字,值可以是任意数据,如果我们要对一组整数进行排序,那么键就是这些整数本身。
2、Shuffle阶段: 将所有具有相同键的键值对分组在一起,这一步是由MapReduce框架自动完成的。
3、Sort阶段: 对每个组内的键值对按照键进行排序,这一步也是由MapReduce框架自动完成的。
4、Reduce阶段: 对于每个组,输出排序后的键值对,在这个例子中,我们只需要输出排序后的整数列表。
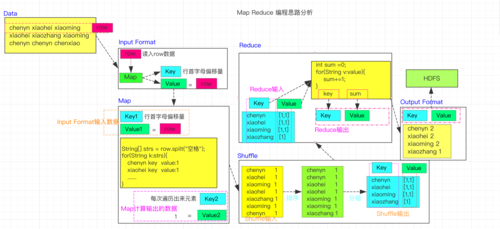
下面是一个简单的Python代码示例,展示了如何使用MapReduce进行排序:
from mrjob.job import MRJob
from mrjob.step import MRStep
class MRSort(MRJob):
def steps(self):
return [
MRStep(mapper=self.mapper, reducer=self.reducer)
]
def mapper(self, _, line):
key = int(line.strip())
yield (key, None)
def reducer(self, key, values):
yield (key, None)
if __name__ == '__main__':
MRSort.run() 这个代码示例使用了mrjob库来实现MapReduce任务,我们定义了一个名为MRSort的类,继承自MRJob,我们定义了steps方法来指定MapReduce的阶段,在这个例子中,我们只有一个阶段,包括mapper和reducer函数。
在mapper函数中,我们将每一行文本转换为一个整数作为键,值为None,这是因为我们只关心排序,而不关心具体的值,我们在reducer函数中简单地输出键,这样最终得到的输出就是排序后的整数列表。
FAQs
Q1: MapReduce如何确保数据的一致性?
A1: MapReduce框架通常提供了容错机制来确保数据的一致性,在Map阶段,如果某个节点发生故障,框架会自动重新分配该节点的任务到其他节点上执行,在Reduce阶段,如果有多个相同的键值对需要合并,框架会将这些键值对发送到同一个reducer进行处理,以确保结果的正确性,MapReduce还支持持久化中间结果,以便在任务失败时可以从上次成功的地方继续执行。
Q2: MapReduce中的Shuffle阶段是如何工作的?
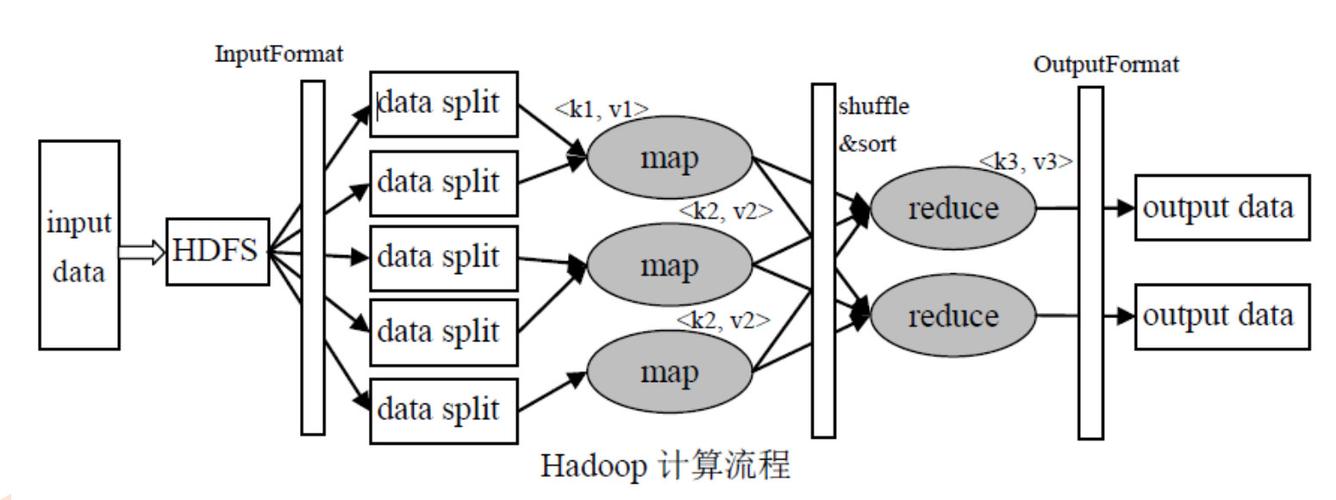
A2: Shuffle阶段是MapReduce中的一个关键步骤,它将Map阶段的输出按照键进行分组,MapReduce框架会根据键值对中的键来决定它们应该发送到哪个reducer,这个过程通常是基于哈希函数的,即根据键的哈希值来确定其所属的组,一旦所有的键值对都被正确地分组,每个reducer就会收到属于它的那部分数据,这个过程可以确保具有相同键的所有键值对都在同一个reducer中进行处理,从而实现了数据的局部性优化。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/938484.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复