


随着信息技术的迅猛发展,大数据已经成为互联网行业内不可或缺的一部分,面向大数据的开源推荐系统因其处理海量数据集的能力而受到广泛关注,这类系统能够有效地从大量数据中提取有用信息,向用户推荐相关物品或服务,提高用户体验,本文将深入分析面向大数据的开源推荐系统,探讨其架构、特点及适用场景,帮助读者更好地理解这一技术。
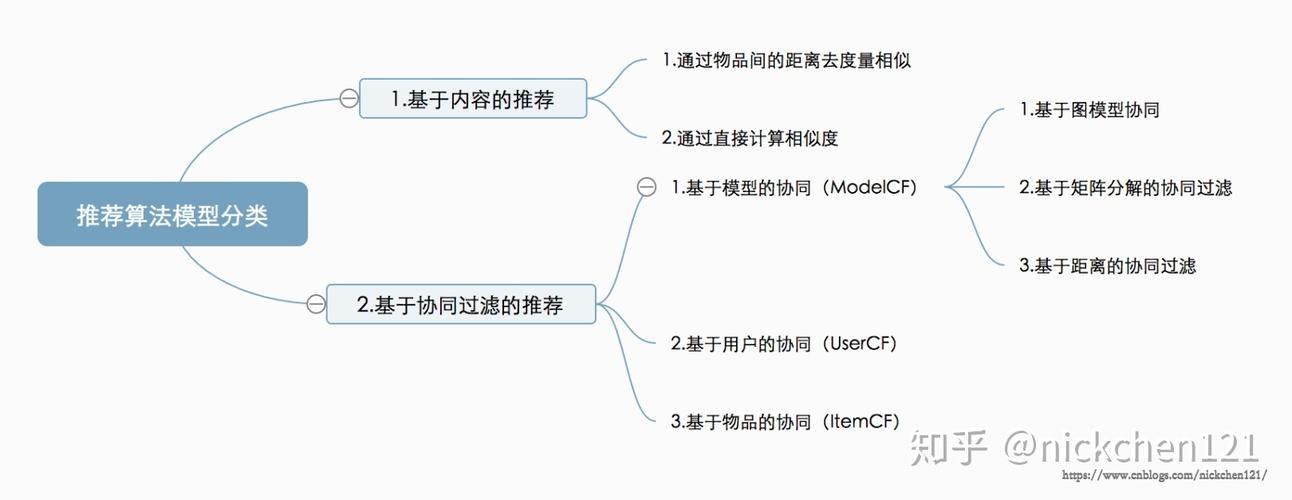

系统架构设计
面向大数据的开源推荐系统通常采用分层架构设计,以提高系统的灵活性和扩展性,这种架构主要包括三个层次:用户交互层、推荐引擎层以及计算存储层,每一层都承担着不同的功能,而层与层之间保持低耦合、高内聚的特性,确保了系统的高效运行,通过分离推荐逻辑与业务逻辑、存储与计算任务,该架构支持模块间的灵活组合,提升了系统的可靠性和扩展性。
核心特点
1、高扩展性:系统设计允许其轻松扩展以支持更多用户和数据,适应日益增长的服务需求。
2、模块化:各功能模块独立,便于单独优化和升级,增强了系统的可维护性。
3、数据处理能力:能够处理和分析大规模数据集,挖掘用户行为和偏好,提供个性化推荐。
4、开源性质:鼓励社区贡献,不断迭代更新,保证了系统的持续进步和适应性。
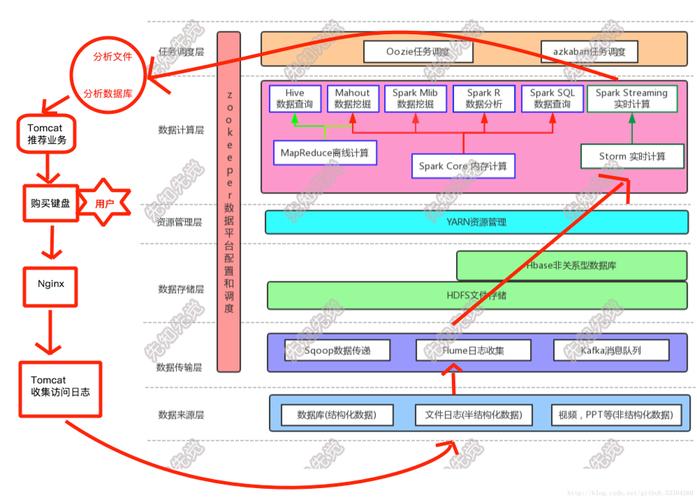
应用场景
面向大数据的开源推荐系统适用于多种场景,包括但不限于电子商务网站的商品推荐、新闻平台的新闻推荐、视频网站的观看建议等,这类系统也广泛应用于社交网络服务中,如好友推荐、内容推荐等。
主要挑战及解决策略
1、数据隐私和安全:在处理大规模用户数据时,必须确保数据的安全性和用户的隐私权益,采取加密技术和严格的数据访问控制是常见的解决方案。
2、系统性能:随着数据量的增加,保持系统的高性能是一个挑战,采用高效的算法和数据结构,以及分布式计算框架(如Apache Hadoop和Apache Spark)可以有效提升处理速度和推荐质量。
未来发展趋势
随着人工智能技术的不断发展,预计未来面向大数据的开源推荐系统将更加智能化,能够提供更准确的推荐,随着云计算技术的普及,这些系统可能会更多地迁移到云端,以利用云平台提供的弹性资源管理和计算能力。
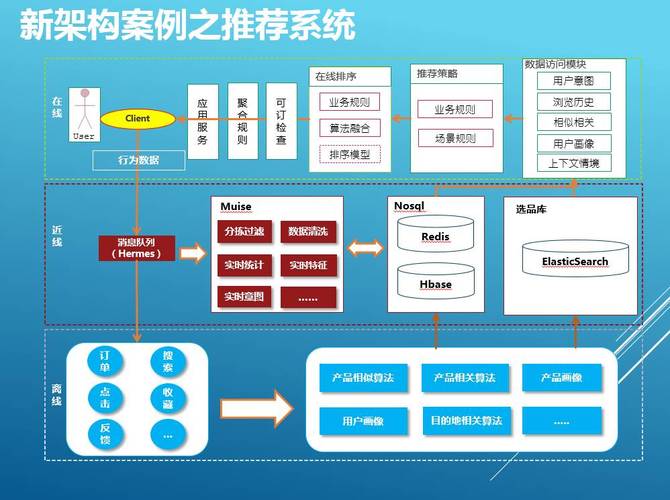
相关技术
值得一提的是,一些开源项目如Gorse提供了通用的推荐系统框架,它使用Go语言编写,易于集成到各种在线服务中,基于Apache Hadoop和Apache Spark的大数据处理平台如EMapReduce和DataWorks,也为推荐系统的数据分析和处理提供了强有力的技术支持。
FAQs
什么是大数据开源推荐系统?
答:大数据开源推荐系统是一种利用开源技术构建的系统,用于处理和分析大规模数据集,以便向用户提供个性化的推荐,这类系统因其能够处理海量数据并从中提取有价值信息而受到重视。
为什么选择开源推荐系统?
答:开源推荐系统具有成本效益高、社区支持强大、透明度高和高度可定制等优势,它们允许企业以较低的成本实施先进的推荐技术,同时受益于全球开发者社区的持续改进和技术支持。
面向大数据的开源推荐系统以其强大的数据处理能力和灵活的架构设计,为现代企业提供了一个高效、经济的解决方案来改善用户体验和提升业务效率,随着技术的不断进步,这些系统将继续发展,更好地服务于各行各业。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/937968.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复