


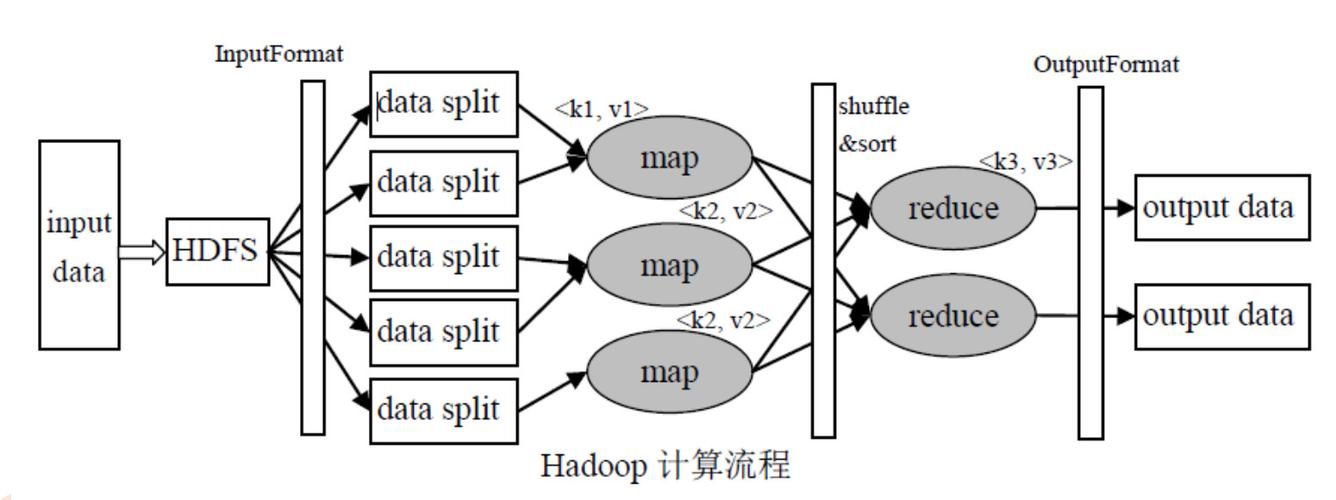
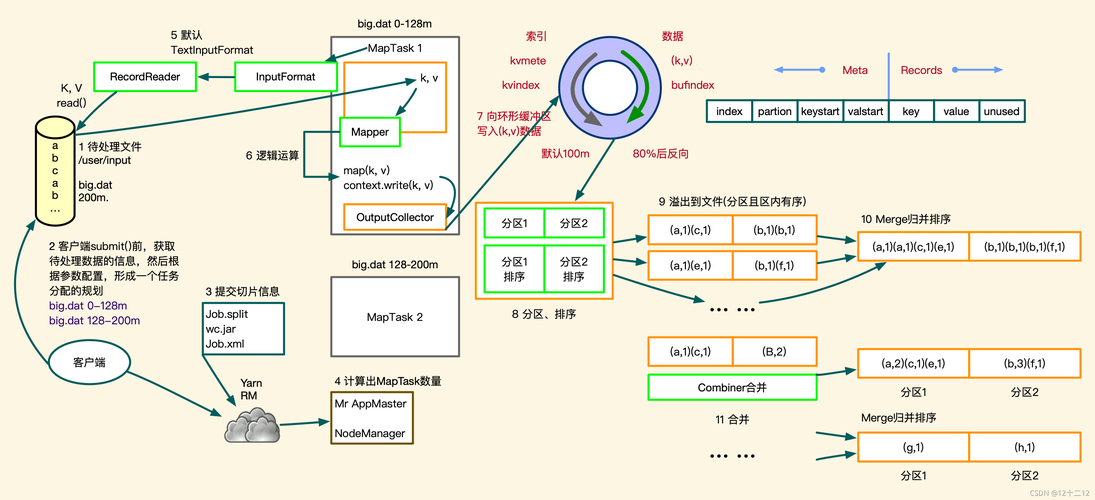
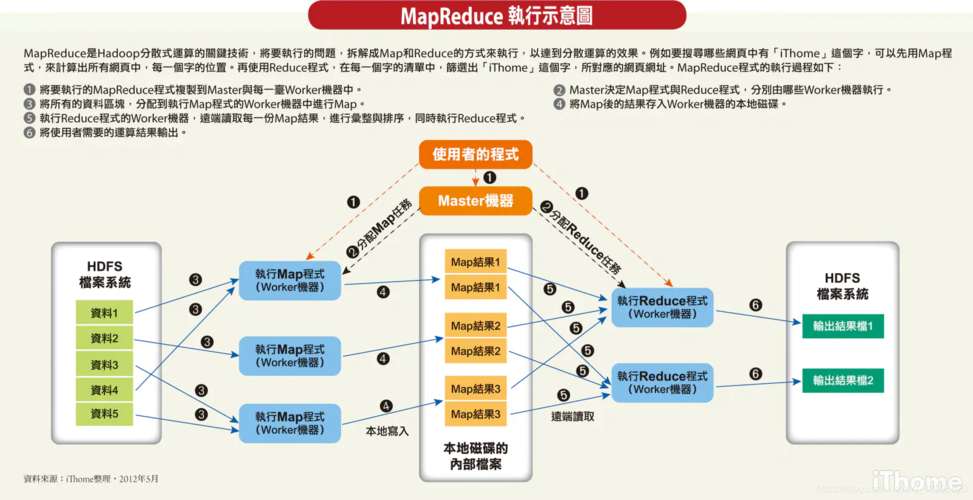
MapReduce是一个编程模型,用于处理和生成大数据集,这个模型主要包括两个阶段:Map阶段和Reduce阶段,在Map阶段,系统将输入数据分成多个独立的块,这些块由多个Map任务并行处理,每个Map任务会生成一组中间键值对,系统会根据键对这些中间结果进行排序,并把它们送到对应的Reduce任务,在Reduce阶段,每个Reduce任务负责处理一个特定键的所有值,以生成最终的输出文件,具体分析如下:

1、MapReduce与其他文件系统的集成
接口实现:要让MapReduce使用其他文件系统或数据库系统,这些系统需要提供JAVA访问的API,开发人员必须实现包括Map、Reduce、InputSplit、InputFormat、RecordReader、OutputFormat、RecordWriter等接口。
数据流:MapReduce任务通常采用分布式文件系统中的数据,例如HDFS,它支持快速数据存储和并行访问,在非Hadoop环境中,输入数据可能来自如GFS这样的底层分布式文件系统,中间数据存放在本地文件系统,而最终输出数据则写回底层分布式文件系统。
文件系统多样性:除了HDFS外,还有其他的分布式文件系统,如GlusterFS和QFS,以及对象存储如Amazon S3,这意味着MapReduce可以与多种存储解决方案配合使用,只要它们提供了相应的接口和API支持。
2、MapReduce架构的扩展性与集成
MRv1的限制:Hadoop 1.0中的MapReduce实现(MRv1)具有一定的限制,如JobTracker单点故障和有限的多框架支持,这推动了后续版本中对MapReduce架构的改进,以支持更好的扩展性和容错性。
YARN的支持:为了解决MRv1的局限性,Hadoop 2.0引入了YARN(Yet Another Resource Negotiator),它可以支持多种计算框架,而不仅仅是MapReduce,YARN为各种文件系统提供了更灵活的资源管理和调度能力。
系统集成:通过YARN,MapReduce可以更轻松地与其他文件系统集成,因为YARN本身就是设计来容纳不同类型数据处理框架的,这使得MapReduce能够利用更多种类的文件系统,优化数据处理流程。
3、未来的趋势与挑战
多样化的数据源:随着数据源的多样化,MapReduce需要适应更多的文件系统和数据格式,这要求它持续更新和改进API和接口。
性能优化:处理大规模数据集时,性能是关键,优化MapReduce与各种文件系统集成的性能,将是未来发展的重点之一。
云服务兼容性:随着云计算服务的普及,MapReduce可能需要更好地与云存储服务集成,比如Amazon S3,以便于在云环境中处理数据。
MapReduce作为一个强大的数据处理框架,其与其他文件系统集成的能力极大地扩展了其应用范围,尽管存在一些挑战和局限性,但随着技术的发展和新的架构设计,如YARN的出现,MapReduce正变得越来越灵活,能够更好地适应不同的文件系统和数据源,人们可以期待MapReduce会在提高性能、优化资源管理以及增强云服务兼容性等方面取得更大的进展。
FAQs
Q1: MapReduce是否可以和其他数据库系统集成?
A1: 是的,MapReduce可以通过数据库系统提供的JAVA API与其他数据库系统集成,这要求实现特定的接口,如Map、Reduce等,以便在MapReduce框架中使用数据库中的数据。
Q2: Hadoop 2.0中的YARN解决了哪些MRv1存在的问题?
A2: YARN解决了MRv1中的一些关键问题,包括提升了系统的扩展性、容错性和多框架支持,它通过提供一个通用的资源管理平台,使Hadoop能够支持除MapReduce之外的其他计算框架。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/937257.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复