


在当今大数据技术的背景下,MapReduce编程模型已成为处理大规模数据集的重要工具,Hadoop框架实现的MapReduce不仅继承了谷歌原始模型的核心思想,还开放源代码供广大用户和开发者使用和修改,本文旨在深入探讨如何修改Hadoop源码,特别是针对其NativeIO类的潜在修改方法及其背后的原理。

修改Hadoop源码的必要性
在讨论具体的源码修改方法之前,了解为何需要修改Hadoop源码是必要的,Hadoop虽然为大数据处理提供了一个可靠的框架,但不同的应用场景往往需要特定的优化和定制,处理特别大的文件时,可能需要优化I/O操作的效率,或者为了适应特定的安全策略,需要修改认证和授权机制,这些需求驱使开发者进入源码层面进行相应的调整和优化。
修改源码的另一个重要原因是提高性能,尽管Hadoop已经经过高度优化,但在面对特定的数据集和计算模式时,进一步的性能提升往往需要依赖于底层代码的调整,这包括但不限于改进算法效率、减少网络传输负载、优化数据存储格式等。
修改Hadoop源码的基本步骤
1、环境准备:首先需要设置好开发环境,包括安装Java开发工具包(JDK)、配置Maven或Gradle作为构建工具,以及确保有足够的系统资源编译大规模的Hadoop项目代码,建议使用Linux操作系统,因为它是Hadoop主要运行的平台。
2、获取源码:下载最新的Hadoop源码包,解压到本地开发环境中,可以从官方网站或者通过版本控制系统如Git获取源码。
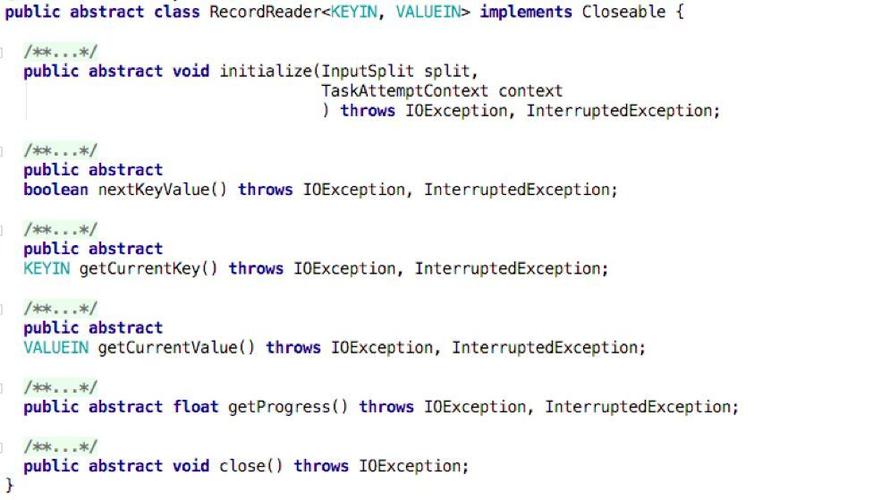
3、代码修改:根据需求修改源码,常见的修改包括但不限于NativeIO类的优化、增加新的功能模块、改进现有算法等,对于I/O类的修改,通常涉及到对文件读写操作的优化,如调整缓冲区大小、改变文件扫描方式等。

4、编译与测试:修改后的源码需要重新编译,并通过单元测试验证修改的正确性,Hadoop项目通常包含丰富的测试用例,确保每个功能模块的稳定性和可靠性。
5、部署与验证:将编译好的Hadoop部署到测试环境中,通过运行实际的数据处理任务来验证修改的效果,这一步骤是确保修改达到预期目的的关键。
NativeIO类的潜在修改
对于NativeIO类的修改,开发者需要关注以下几个关键点:
性能优化:考虑到数据读取的速度直接影响整个MapReduce作业的执行效率,可以通过调整I/O操作的并发级别或优化文件读取缓存机制来提升性能。
容错性增强:增强错误处理逻辑,确保在读取文件过程中遇到错误能够优雅地处理,比如支持自动恢复读取进度或跳过不可读的数据块。
安全加固:加强权限检查和身份验证过程,避免非法的文件访问请求,保护数据的安全和完整性。
相关案例分析
以气象数据处理为例,通过修改Hadoop的MapReduce代码和整合SSM框架,可以有效地处理和展示气象数据,这种类型的案例展示了如何通过修改和扩展Hadoop源码来满足特定行业的需求。
考虑到Hadoop生态系统的复杂性,修改源码时还需注意以下几点:
确保修改不会影响Hadoop框架的其他部分,尤其是不破坏已有的API和功能。
修改后的代码应当遵循原有的编码规范和文档标准,以便于社区的贡献和维护。
进行全面的性能测试和稳定性测试,确保修改带来的提升不会牺牲其他重要的系统属性。
修改Hadoop源码是一项复杂而深入的工作,需要开发者具备扎实的Java基础、对Hadoop架构和原理有深入理解,以及对分布式系统的挑战有充分的认识,通过细致的计划、谨慎的执行和全面的测试,可以有效地对Hadoop进行定制化改进,以满足特定的业务和技术需求。
FAQs
1. 修改Hadoop源码会影响系统稳定性吗?
答: 可能会影响,任何对核心系统的修改都需要经过严格的测试来确保不影响系统的整体稳定性,建议在沙箱环境中进行广泛的测试后,再考虑在生产环境中部署修改后的系统。
2. 如何确保修改后的Hadoop系统安全性?
答: 修改源码时应遵循最小权限原则,并加强代码的安全性审核,利用自动化安全测试工具检测潜在的安全漏洞,确保所有修改都符合安全最佳实践。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/937111.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复