


MapReduce是Google提出的一种编程模型,适用于大规模数据集的并行处理,它通过将作业分解为两个阶段——Map阶段和Reduce阶段——来简化数据处理过程,下面将详细探讨MapReduce中的块划分机制,特别是数据划分的核心概念与实现方式,以及如何有效地进行区块划分。

MapReduce 块划分原理
1、基本概念
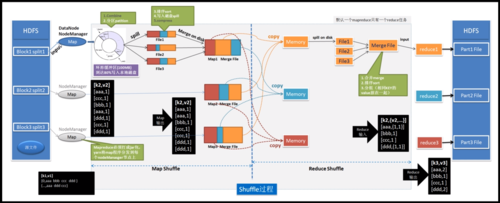
数据划分: 在MapReduce框架中,输入数据首先需要被切割成多个数据块,每个块被称为一个“split”,这个过程是MapReduce作业执行的起点,直接关系到后续任务的分配和数据本地化优化。
数据块大小: 数据块的大小设置为64MB或128MB,这样的设置允许各个Map任务独立处理相应的数据块,而无需担心单个任务处理数据过大导致的性能瓶颈。
逻辑到物理的映射: 虽然在MapReduce中数据以“split”形式存在,但在HDFS(Hadoop分布式文件系统)中,数据实际是以固定大小的“block”存储的,这意味着在物理存储层面,数据块(block)和逻辑上的数据划分(splits)需要相互对应,以优化数据的读取和网络传输效率。
2、块划分的重要性
提高并行处理能力: 通过将大数据集划分为多个小块,可以使得多个节点同时工作在不同的数据块上,显著提升处理速度和系统吞吐量。
数据本地化优化: MapReduce框架尽量将数据处理任务分配给存有相应数据块的计算节点,减少网络I/O,从而加速数据处理过程。
容错性和扩展性: 当某个处理节点失败时,只需在其上重新执行对应的小数据块任务,而不必重启整个作业,这种模型也便于按需增加或减少处理节点。
3、划分策略
均匀划分: 为确保各计算节点负载均衡,输入数据通常需要均匀划分,即每个数据块的大小尽可能一致,这有助于避免某些节点因数据过多而成为性能瓶颈。
动态划分: 根据数据的特性和处理需求,有时需要动态调整数据块的大小和划分策略,以适应不同类型数据的处理,如结构化数据与非结构化数据的处理差异。
4、实现细节
InputFormat: 在Hadoop中,InputFormat负责定义如何分割和读取数据。TextInputFormat是默认的实现,它按行分割文本数据。
自定义划分: 对于特定的应用,开发者可以通过自定义InputFormat来控制如何切分数据,这对于特定类型的数据(如图像、视频等)非常关键。
5、性能考量
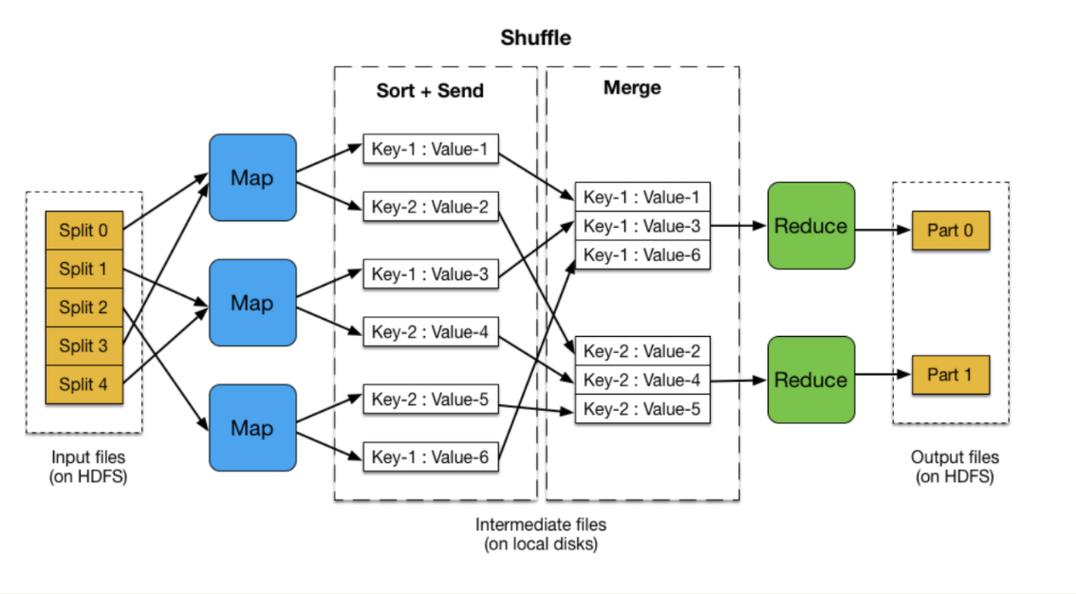
网络传输优化: 在Shuffle阶段,需要将分散的Map输出结果传输并聚合到Reduce节点,优化数据传输顺序和压缩可以显著改善此阶段的性能。
存储优化: 数据块的存储应考虑节点间的负载均衡及数据的安全备份,通常采用多副本策略确保数据的可靠性和可用性。
区块划分的实际应用
1、矩阵运算
分块矩阵乘法: 在科学计算中,通过将大矩阵分为多个子矩阵,可以并行处理这些子矩阵的乘法,从而高效利用计算资源,加快运算速度。
分布式存储: 分块后的矩阵可以在不同的计算节点上进行存储和处理,每个节点负责一部分子矩阵的操作,这样可以在分布式环境中实现高效的矩阵运算。
2、图形处理
图像分割: 在处理大型图像或进行复杂图像分析时,将图像分割成较小的区块,每个区块单独进行处理,可以显著提高处理速度和并行度。
实时图像处理: 对于需要实时处理的应用(如视频监控分析),区块划分能够降低单节点的处理压力,通过并行处理达到实时分析的效果。
相关问答FAQs
Q1: MapReduce如何处理非结构化数据?
A1: MapReduce通过自定义InputFormat来处理非结构化数据,开发者可以编写特定的解析方法来识别和提取非结构化数据中的信息,然后将其转换为MapReduce可以处理的键值对格式,这种方式使得MapReduce不仅限于处理文本数据,也能广泛应用于其他多种数据类型,如图像、视频等。
Q2: 在进行MapReduce作业时,如何优化Shuffle阶段的性能?
A2: 优化Shuffle阶段的性能主要可以从以下几个方面入手:
数据压缩: 在数据传输前对数据进行压缩,减少需要传输的数据量。
数据传输调度: 优化数据传输的顺序,尽量减少网络拥塞和传输延迟。
使用高速网络连接: 在硬件条件允许的情况下,使用更快的网络连接可以明显改善数据传输速度。
增加并行度: 通过调整Map和Reduce任务的数量,增加作业的并行度,可以有效缩短Shuffle阶段的执行时间。
各项措施可以帮助改善MapReduce作业在Shuffle阶段的执行效率,提升整体作业的运行速度。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/935719.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复