


【mapreduce bigtable_MapReduce】

探索Google如何通过MapReduce和BigTable革新大数据处理领域,揭示其核心技术及相互联系。
MapReduce:分布式编程模型的基石
MapReduce,一个专为大规模数据集设计的分布式编程模型,由Google开发,以支持对海量数据进行高效的处理,此模型核心在于“Map”和“Reduce”两个步骤,分别负责数据的分解处理和结果的聚合计算。
Map阶段的独立性
在Map阶段,输入的数据被分成多个独立的数据块,每个数据块由不同的节点并行处理,这一过程确保了数据处理的高度并发性,显著提高了计算速度,由于Map操作是确定性的,不依赖于外部状态或中间状态,因此极大地方便了系统的容错设计。
Reduce阶段的角色
经过Map阶段的处理后,中间结果需通过Reduce阶段进行汇总,以得到最终的计算结果,Reduce步骤将所有Map步骤的输出作为输入,通过对这些中间结果的处理和归纳,得到简洁明了的最终答案。
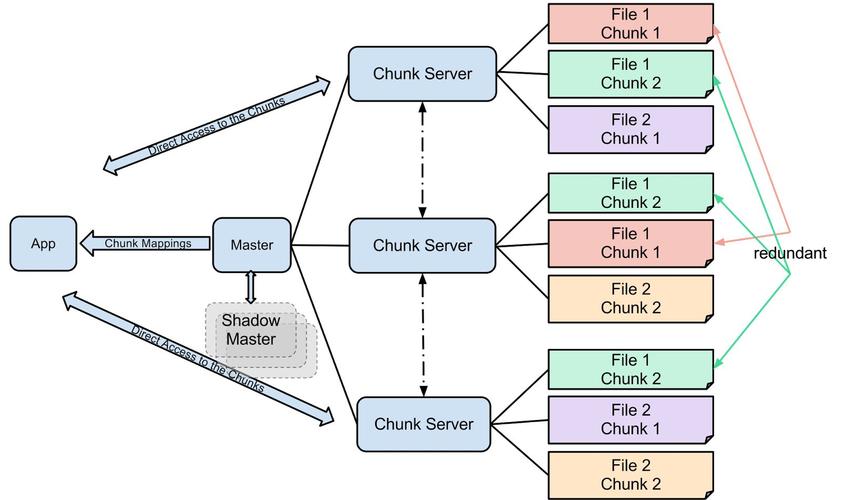
系统架构
MapReduce系统中包含两种主要节点:Master和Worker,Master负责整个程序的调度和管理,而Worker则执行实际的Map或Reduce任务,这种结构设计有效地分散了计算负载,同时保证了系统的灵活性和扩展性。
BigTable的特性与优势
作为Google的另一项核心技术,BigTable是一种用于管理结构化数据的分布式存储系统,它不仅保留了关系型数据库的一些优点,如数据一致性和结构化查询,还加入了分布式存储和动态伸缩性等现代特性。
与MapReduce的互补性
BigTable虽然与MapReduce有各自独立的角色和功能,但两者在实际应用中常常协同工作,MapReduce可以高效处理和分析BigTable中存储的数据,而BigTable则为MapReduce提供稳定、可靠的数据存储服务。
GFS、MapReduce和BigTable的整合
这三种技术共同构成了Google强大的数据处理和存储体系,GFS(Google File System)提供基础的存储解决方案,MapReduce框架在其上进行高效的数据处理,而BigTable则作为高级的数据存储方案,为复杂的查询和大规模的数据分析提供支持。
通过以上分析,我们可以看到MapReduce和BigTable在大数据领域的重要作用及其相互补充的关系,Google通过这三者的创新结合,不仅解决了数据存储和处理的规模化问题,还推动了大数据技术的发展。
进一步地信息汇总与应用策略
随着数据量的持续增长,了解并利用MapReduce和BigTable的特性将变得越发重要,企业可以通过这两者的结合使用,优化他们的数据处理流程,提高数据分析的效率和准确性。
相关问答FAQs
Q1: MapReduce如何处理失败的任务?
A1: MapReduce通过master节点来监控所有worker的状态,如果某个任务失败,系统会重新安排这个任务到其他worker节点上执行,由于Map和Reduce操作具有无状态的特性,这种重新执行不会影响到整体的处理结果。
Q2: BigTable与MapReduce在实际应用中的协作方式是怎样的?
A2: 在实际应用中,BigTable通常用于存储需要频繁读写和查询的大量结构化数据,当需要进行复杂的数据分析时,MapReduce可以从BigTable中读取数据,进行并行处理,处理完毕后,可以将结果再次写回BigTable或用于其他用途,这种协作模式充分利用了BigTable的数据存储能力和MapReduce的数据处理能力,提高了整个系统的效能和灵活性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/935423.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复