

_INPUT表示输入数据,通常是一个文件或文件夹的路径。在本地模式下,这个路径应该是你本地计算机上的一个有效路径。如果你有一个名为input.txt的文件,你可以将其作为输入数据传递给MapReduce程序。在MapReduce编程模型中,InputFormat组件扮演着至关重要的角色,它负责将存储在HDFS (Hadoop Distributed File System) 上的数据转化为键值对,以便MapTask进一步处理,下面将深入探讨MapReduce的InputFormat,特别是默认的_INPUT格式,以及如何自定义InputFormat和RecordReader来满足特定的数据处理需求。
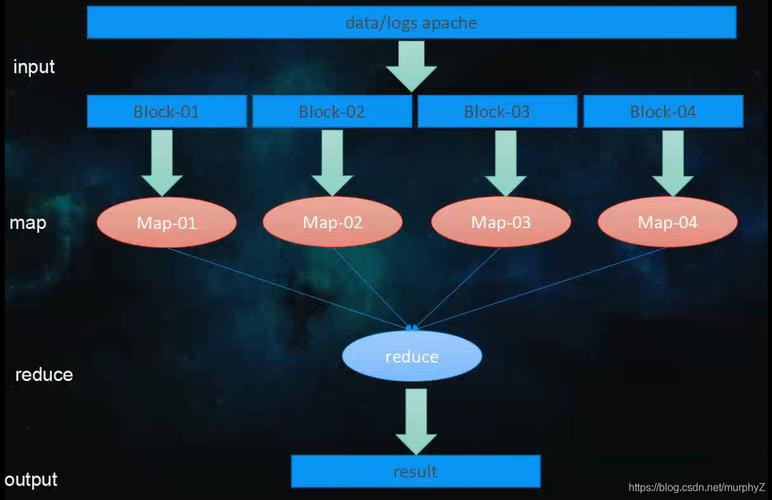

MapReduce中的InputFormat基础
MapReduce编程模型的核心思想是将大数据集分解成小数据块,这些数据块独立地由多个Map任务处理,然后通过Reduce任务将结果汇总,在这一过程中,InputFormat负责数据的输入格式和划分,它主要完成两个任务:一是将文件切分成逻辑上的InputSplit;二是通过RecordReader将InputSplit解析成键值对。
默认的_INPUT格式
在大多数情况下,开发者会直接使用Hadoop提供的默认InputFormat,如TextInputFormat,这种格式假设输入文件是文本文件,按行切割,每行生成一个键值对,键是字符偏移量,值是该行的文本内容,对于二进制文件或特定结构的文件(如XML、CSV),默认的InputFormat可能不适用,此时就需要自定义InputFormat和RecordReader。
自定义InputFormat和RecordReader
自定义InputFormat和RecordReader允许开发者根据具体的文件格式和数据处理需求,灵活地控制数据如何被读取和解析,处理XML文件时,可以定义一个继承自InputFormat的类,并实现records的具体读取方式;还需要定义一个RecordReader类,用于将InputSplit解析为键值对,通过这种方式,可以有效地处理复杂的数据格式,提高数据处理的灵活性和效率。
处理小文件的挑战
在Hadoop环境中,处理大量小文件是非常低效的,每个小文件都会生成一个Map任务,导致大量的磁盘I/O操作和计算资源的浪费,为了解决这个问题,可以通过自定义InputFormat来实现小文件的合并,这通常涉及到预合并小文件到一个较大的文件中,并在MapReduce作业开始前将其作为一个单独的输入分割。
高级应用:基于文件内容的KeyInputFormat
在某些场景下,需要按照文件内容而非文件行来生成键值对,如果键是一个由文件名和记录位置组成的复合键,则需要实现一个FileKeyInputFormat类和一个FileKeyRecordReader类,这种情况下,InputFormat不仅要负责文件的切分,还要能够理解和解析文件内部的逻辑结构。
通过上述讨论,可以看到InputFormat在MapReduce编程模型中的重要性,以及如何通过自定义InputFormat和RecordReader来满足特定的数据处理需求,将通过FAQs形式解答与InputFormat相关的常见问题。
相关问答FAQs
Q1: 如何选择合适的InputFormat?
A1: 选择InputFormat时,首先考虑的是输入数据的类型和结构,对于简单的文本数据,可以使用默认的TextInputFormat;对于二进制数据或特定格式的文件,如XML、CSV,应考虑自定义InputFormat和RecordReader,考虑到数据的大小和分布,选择合适的InputFormat也有助于优化作业执行效率。
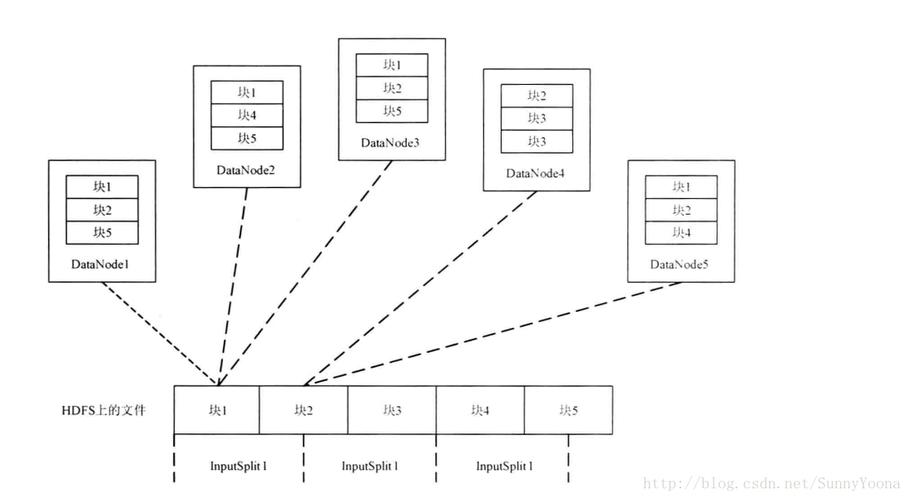
Q2: 自定义InputFormat的性能考量有哪些?
A2: 自定义InputFormat时,性能考量主要包括减少I/O操作、合理划分输入数据以避免数据倾斜、以及优化数据解析过程以减少CPU消耗,特别是在处理大量小文件时,考虑预先合并小文件可以显著提高性能。
MapReduce的InputFormat是一个功能强大且灵活的组件,它决定了数据的输入格式和处理方式,理解其工作原理和如何自定义InputFormat及RecordReader,对于高效处理大数据至关重要,通过合理选择和设计InputFormat,可以有效提升数据处理的效率和灵活性。
原创文章,作者:未希,如若转载,请注明出处:https://www.kdun.com/ask/935377.html
本网站发布或转载的文章及图片均来自网络,其原创性以及文中表达的观点和判断不代表本网站。如有问题,请联系客服处理。
发表回复